一份关于美联储的报告(下):政策工具箱与宏观经济指标的运作逻辑
本期详解美联储常规与非常规政策工具,及其调控信贷实现双重目标的机制。并探讨贝莱德等三大资管巨头日益增长的影响力及其与美联储的复杂联动关系。
17044 字|85 分钟
本期详解美联储常规与非常规政策工具,及其调控信贷实现双重目标的机制。并探讨贝莱德等三大资管巨头日益增长的影响力及其与美联储的复杂联动关系。
这篇博客详细介绍了治疗失眠和抑郁的药物,强调用药需遵医嘱,切勿擅自使用。文章分类介绍了抗失眠药物(苯二氮䓬类、非苯二氮䓬类、褪黑素受体激动剂、食欲素受体拮抗剂、镇静抗抑郁药)和抗抑郁药物(SSRIs、SNRIs、TCAs、MAOIs、非典型抗抑郁药)的作用机制、常见药物、风险和副作用。

阿里小开了一款大模型,叫Qwen2.5-Omni,本篇将看下Qwen2.5-Omni的技术报告,讨论一下其中的创新点和Omni类模型的工程优势。

本文深入解析 DeepSeek V3 和 R1 两大模型的创新点,涵盖架构、训练策略与推理能力,展现中国开源模型的强劲进展与高性价比潜力。
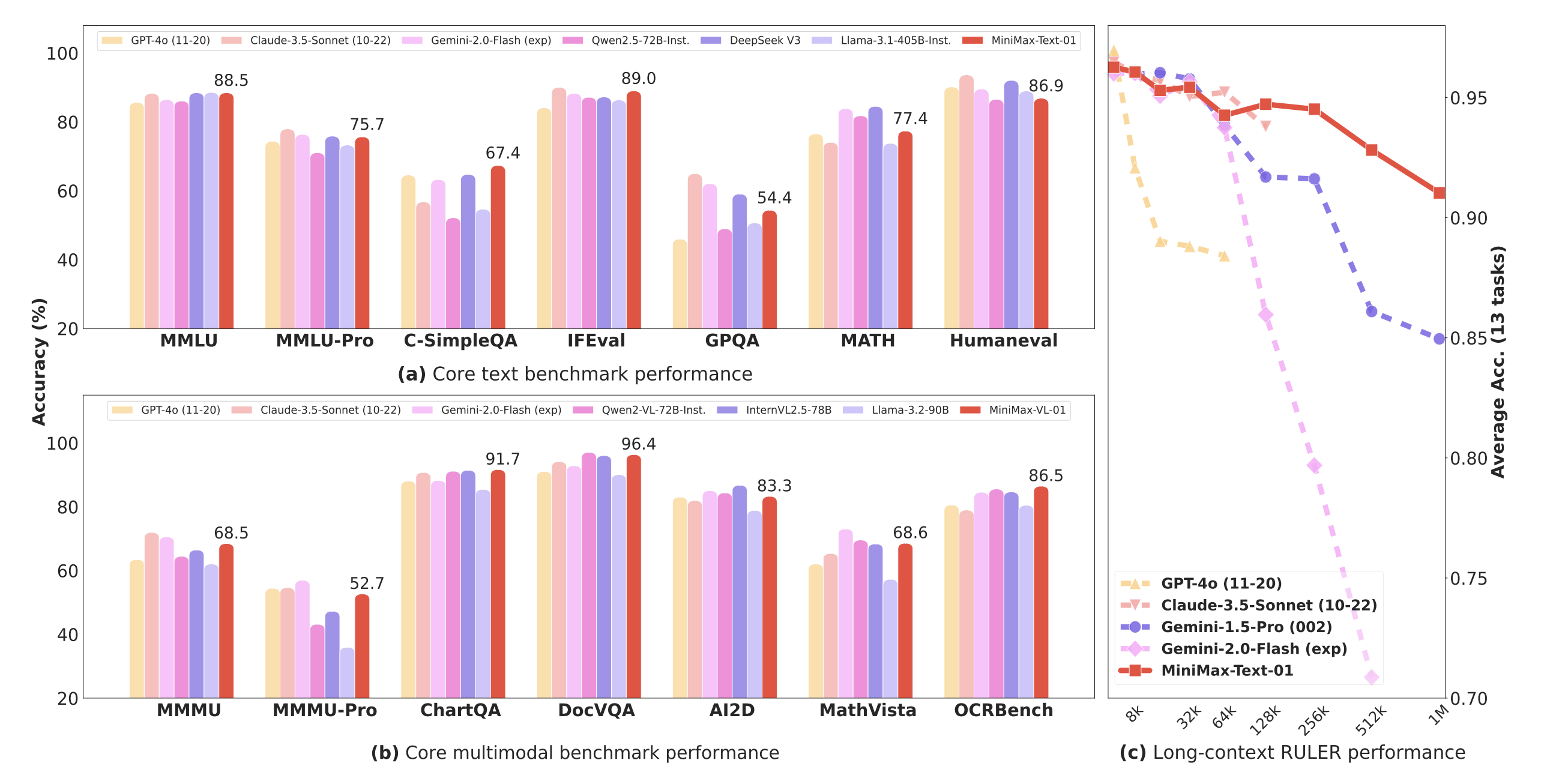
本篇博客简要解析了 Minimax-01 模型的架构设计,聚焦其在超长上下文处理中的性能表现与混合注意力机制的技术实现。

The BigIdeas 2025的分析报告Part2,主要内容为Robotaxi、自动物流和可重复利用火箭三个领域的解析