一、技术选型:少即是多
在做 Agent 之前,我当然看了一圈市面上现成的方案。Vercel AI SDK、LangGraph、还有各家模型厂商自己的 Agent SDK,选择很多。但看完之后我反而更坚定了自(ai )研的想法。
原因倒不是什么”它们不够好”或者”场景太特殊适配不了”这种高大上的理由。核心原因很朴素:Agent Loop 这件事本身就没那么复杂,不需要一个重型框架来承载它。
最近大火的 clawdbot(就是那个小龙虾机器人🦞)其实侧面印证了这一点。它的核心 agent 引擎 pı 极其精简,clawdbot 本身则更像一个 cron + Claude Code,但它能接管你电脑上的一切,star 已经飙到几百 K 了。这说明什么?说明 agent 的价值不在于编排框架有多精巧,而在于它能不能可靠地把工具用起来,把事情做完。
回到 YOLO 自己的场景。一个 Agent Loop 的本质是什么?就是一个循环:
- 把消息发给 LLM
- LLM 返回内容,判断有没有 tool call
- 有的话执行工具,把结果塞回消息列表
- 回到第 1 步,直到模型觉得”做完了”不再调用工具
就这么简单。你当然可以在这个循环上叠加各种花活:状态机、DAG 编排、定时任务、多 agent 协作、动态规划……但对于 YOLO 来说,一个 Obsidian 插件,用户在笔记库里和 AI 对话、让它帮忙读写文件、整理笔记,这个基本循环就完全够用了。把简单的事情用简单的方式做好,比用复杂的框架做出”看起来很厉害但实际上也就那样”的效果要强得多。
至于 Provider 层和工具层的选型,没什么可纠结的。Provider 层按渠道用官方 SDK(Anthropic SDK、OpenAI SDK 等),总不能自己手写 HTTP 请求去处理流式响应和各种边界情况吧,这属于没苦硬吃。工具协议选 MCP,因为它就是目前事实上的标准规范,没有第二个选择。
所以 YOLO 的技术选型策略可以用一句话概括:编排层自研,接入层用官方 SDK,工具层走 MCP。 自研的部分尽量薄,只做必须自己控制的事情;能用标准方案的地方绝不重复造轮子。
二、Agent Loop 的实现
先放一张整体架构图,后面的内容基本上都是围绕这张图展开的:
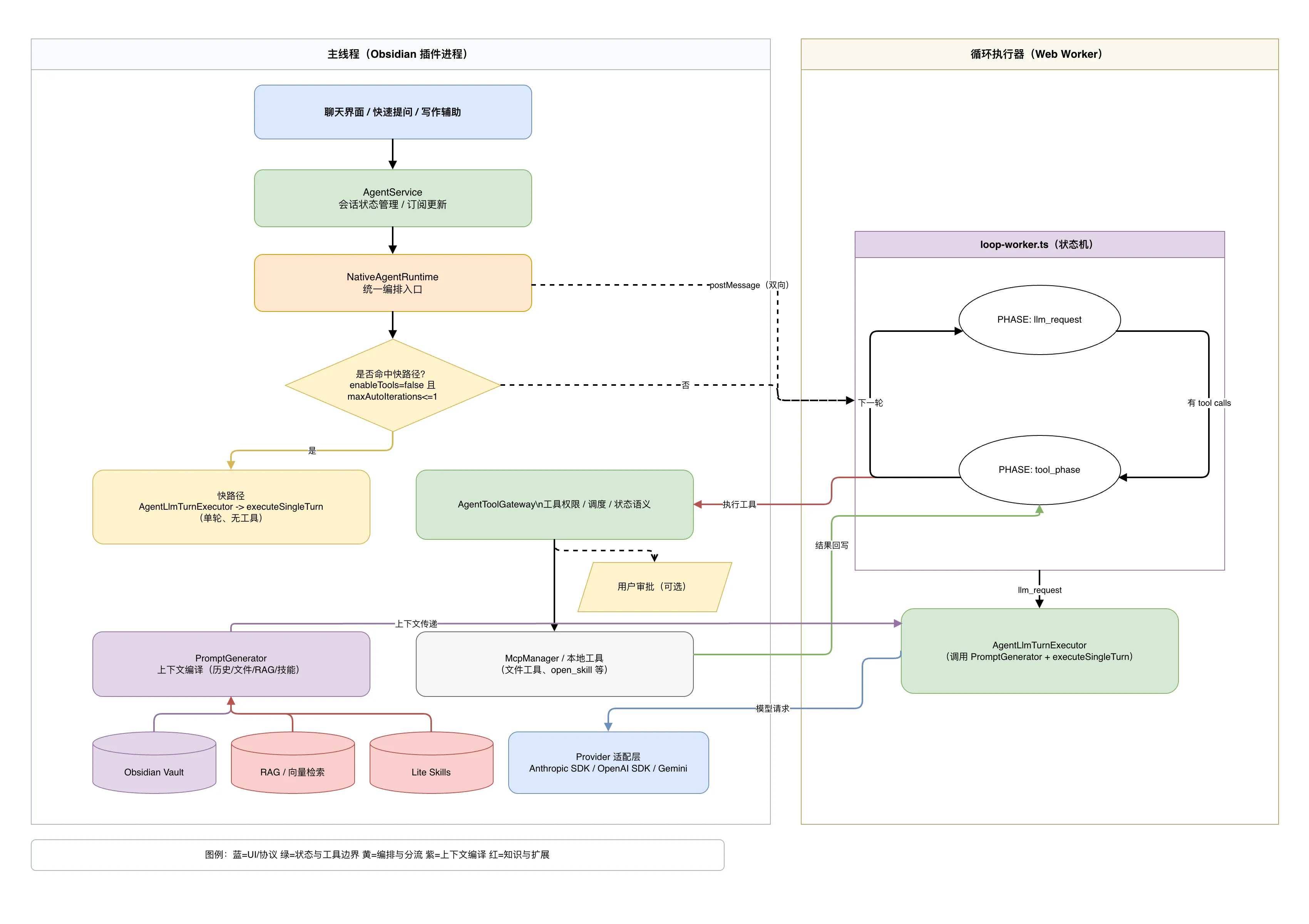
一切的起点:三种场景,一个内核
YOLO 里用到 LLM 的地方不止 Agent Chat 一个。Smart Space 和 Quick Ask 需要 LLM,补全和未来的建议&关联文档也需要 LLM。一个很自然的问题是:这么多场景需要各写一套调用逻辑吗?
答案当然是不。YOLO 的做法是所有场景共享同一个单轮执行内核 executeSingleTurn,差异只在于上层的 运行时配置(Profile) 不同:
- Quick Ask 等:
enableTools=false,maxAutoIterations=1。不需要工具,问一轮就走,追求低延迟。 - Agent Chat:工具全开,多轮自动迭代,走完整的 loop。
这就是图里最上面 UI 层拉出两条线但最终汇到同一个 Runtime 的原因。用户体验按场景定制,底层能力是同一套东西,即同核多态。
快路径与完整 Loop 的分流
请求到达 NativeAgentRuntime 之后,第一件事是判断走不走快路径。判断条件很简单:enableTools=false 且 maxAutoIterations<=1。
命中快路径的话,直接在主线程跑一次 AgentLlmTurnExecutor,调 executeSingleTurn 拿到结果就结束。没有工具调用,没有循环,没有 Worker 通信开销。Quick Ask 走的就是这条路,所以它的响应速度(理论上)会明显快于 Agent Chat。
没命中快路径的话,事情就有意思了。Runtime 会通过 postMessage 把任务丢到 Web Worker 里,由 loop-worker.ts 这个状态机来接管。
为什么要用 Web Worker?因为 Obsidian 是个 Electron 应用,Agent Loop 可能要跑好几轮 LLM 请求 + 工具执行,如果在主线程跑这些,UI 会卡。把 loop 的状态转移逻辑扔到后台线程,主线程只负责接收状态更新和渲染,界面就不会顿挫了。
loop-worker 内部是一个状态机,核心就两个相位,不断交替:
llm_request 相位:把当前的消息列表(包括之前的工具执行结果)交给 AgentLlmTurnExecutor,它负责调用 PromptGenerator 编译上下文、注入工具定义、发请求给模型、流式处理响应。模型返回之后,看看有没有 tool calls。没有就结束整个 loop,有的话就进入下一个相位。
tool_phase 相位:拿到 tool calls 之后,交给 AgentToolGateway 去调度执行。工具网关会做权限检查(这个工具允不允许用?是不是高危操作需要用户审批?),然后分发到具体的工具实现(MCP 外部工具或本地文件工具)。工具执行完毕,结果回写到消息列表,然后回到 llm_request 相位,开始下一轮。
就这么来回转,直到模型不再调用工具,或者达到了最大迭代次数。
对照前面技术选型里说的那四步循环:发消息 → 判断 tool call → 执行工具 → 回到第一步。loop-worker 做的事情本质上就是这个,只不过工程上多了流式处理、Worker 通信、权限管控这些必要的基建。
工具网关:可控边界内的自动化
工具网关(AgentToolGateway)是我觉得值得单独说一下的模块。它不只是个”转发器”,而是整个工具执行的安全边界。
首先是 权限过滤。每个 Assistant 配置里定义了允许使用的工具列表,运行时还有额外的策略约束。不在白名单里的工具,模型调了也不会执行。
然后是 审批机制。高风险操作(比如文件删除)默认不会自动执行,而是转入审批态,等用户在 UI 上确认之后才继续。这就是架构图里那个”用户审批(可选)“平行四边形的含义。
最后是 统一的生命周期语义。每个工具调用都有明确的状态:pending → running → success/error/aborted。这些状态既供模型在下一轮推理时参考,也供 UI 展示给用户看。用户能清楚地知道 Agent 做了什么、正在做什么、哪些操作成功了哪些失败了。
这套设计的出发点很明确:Agent 可以自动化,但自动化必须在可控边界内。你不会希望 AI 在你的笔记库里静默删掉一堆文件然后跟你说”整理完了”。
上下文编译
架构图底部有一个紫色的模块 PromptGenerator,它从三个数据源获取信息:Obsidian Vault(当前文件、mention 引用)、RAG 向量检索(隐式召回的相关内容)、以及 Lite Skills(技能文档)。
YOLO 对上下文的处理不是简单地把所有东西拼成一个大字符串塞给模型。PromptGenerator 更像是一个编译器,它要做的是:在有限的 token 预算内,把最有价值的信息组装成结构化的 prompt。
具体来说:
- 聊天历史有滑动窗口,不会无限制地往上追溯。
- 当前文件内容过长时会触发摘要或 RAG 降级。
- mention 引用(用户通过
@显式提及的文件)优先级高于隐式召回。 - 工具调用的 request 和 response 成组保留,不完整的结果会被过滤掉。
- Lite Skills 按 always/lazy 两种模式加载,默认 lazy,不会在首轮就把所有技能文档塞进上下文。
上下文是稀缺资源,这一点在之前的文章里已经讨论过了。PromptGenerator 的职责就是在这个约束下做资源分配,确保模型拿到的信息是”够用且精准”的。
三、Lite Skills:精简后的,更适合黑曜石宝宝体质的 skills
Agent Loop 解决了”AI 能做事”的问题,但光能做事还不够。同样是”帮我整理笔记”,不同场景下整理的方式、输出的结构、工具的调用策略可能完全不一样。你可以每次都在对话里把这些要求说一遍,但这太蠢了。
所以需要 Skills。
关于 Skills 的动机,其实在更早之前就想过了。当时的想法是:Skill 和现有的 Assistant(助手预设)有什么区别?区别在于粒度和组合性。Assistant 是一个完整的”人格”,你选了学术写作助手就不能同时选代码审查助手;Skill 是能力模块,天然支持叠加。一个 Assistant 可以装载多个 Skill,就像一个人可以掌握多种技能。
但当时也意识到一个前置条件:如果 YOLO 只是个纯 chatbot,Skills 模块仍然只是提示词雕花,叫”Skills”未免太寡淡了。Skills 这个词让人联想到的是”能力”,是能做事的。所以我选择先把 Agent Loop 做出来,让 AI 有了工具可用、有了执行能力之后,Skills 才真正有用武之地:它不只是改变 AI 说话的风格,而是能影响 AI 如何思考、如何使用工具、如何完成任务。
现在 Agent Loop 已经就位了,该聊 Lite Skill 的设计了。
为什么叫「Lite」
先说结论:YOLO 的 Lite Skills 是 Anthropic Skills 规范的一个大幅简化版本。
Anthropic 原版的 Skills 是一个(或多个)完整的文件夹,结构可以很复杂:核心的 SKILL.md 负责元数据和操作指令,旁边挂着 scripts/ 放可执行脚本、references/ 放技术参考文档、assets/ 放模板和样例。像官方提供的 docx 处理 Skill,光文件就十几个,Python 脚本、XML 模板、OOXML 规范文档一应俱全。这套设计很强大:脚本封装了确定性操作,分层文档实现了渐进式上下文披露,整个 Skill 就像一个自给自足的微型工具包。
但这套东西做不到全量移植到 Obsidian 里,原因有三个层面。
环境层面:Obsidian 插件运行在 Electron 的渲染进程中,天然没有 shell 执行能力。Claude Code 可以直接跑 bash,所以 Anthropic 原版 Skills 捆绑脚本是合理的,Agent 能直接调起来执行确定性操作。但 YOLO 不行,插件环境里你拿到一个 .py 文件也没法跑。这个平台限制从根上决定了脚本捆绑这条路走不通。
用户层面:YOLO 的用户群体是笔记用户,不是开发者,且 Obsidian 的 vault 本质上是一个 markdown 文件库,往里面塞 .py 和 .xml 既不自然也不优雅。
架构层面:YOLO 的工具能力已经通过 MCP 和本地文件工具提供了,Skill 不需要再额外捆绑脚本来执行确定性操作。确定性的活交给工具层,Skill 只负责告诉 Agent「在什么场景下、按什么策略去调用这些工具」。职责分离得很干净。
所以 YOLO 做了简化:一个 Skill 就是一个 markdown 文件。没有文件夹,没有脚本,没有多级引用。所有信息都写在一个 .md 文件里,用 YAML frontmatter 声明元数据(id、name、description、mode),正文就是给 Agent 的操作指令。Skills 文档会放在 vault 的 YOLO/skills/ 目录下,和你的笔记、日记、项目文档住在一起,用 Obsidian 原生的编辑器就能创建和修改。这就是「Lite」的含义:不是功能阉割,是把 Anthropic 那套为专业开发场景设计的重型结构,适配成了 Obsidian 用户能自然使用的轻量形态。
砍掉的东西和保留的东西一样重要,值得明确列一下:
保留了什么:
- 元数据常驻 + 正文按需加载的核心架构
- always / lazy 两种加载模式
- 模型可自主生成 skill 的定制能力
- 双层权限门禁(全局 + Agent 级)
砍掉了什么:
- 脚本捆绑(确定性操作交给 MCP 工具层处理)
- 多级文档引用(单文件内用 markdown 章节结构替代)
- 文件夹式的 Skill 包(一个
.md文件就是一个 Skill)
一个 Skill 长什么样
在系统内部,每个 Skill 被表示为一个叫 LiteSkillEntry 的轻量结构:
{ id: string // 技能唯一标识 name: string // 显示名称 description: string // 功能描述(注入给模型做判断用) mode: 'always' | 'lazy' // 加载模式 path: string // 文件路径}对应到实际文件,一个最简单的 Skill 长这样:
---id: weekly-work-planname: Weekly Work Plandescription: Create and manage weekly work plans.mode: lazy---
# Weekly Work Plan
## 使用场景当用户提到「本周安排」「周计划」「工作安排」时激活。
## 操作步骤1. 检查上周计划的完成情况2. 将未完成的任务迁移到本周3. 按优先级整理新的任务列表...frontmatter 的解析有一套兜底规则:id 没写就用文件名,name 没写就用 id,description 没写就给个默认值,mode 只要不是明确写了 always 就一律当 lazy 处理。这意味着你甚至可以创建一个只有正文、完全不写 frontmatter 的 markdown 文件扔到 YOLO/skills/ 里,系统也能识别它。当然不推荐这么干,description 写不写直接决定了模型能不能在合适的时候找到这个 Skill。
Skill 的来源有两个:
内置技能,是代码里写死的模板。目前有两个:
obsidian-output-format:规范 Agent 输出 markdown 的格式,默认always(因为每次对话都需要)skill-creator:指导用户创建新 Skill 的 meta-skill,默认lazy
Vault 技能,是用户自己在 YOLO/skills/ 目录下创建的 markdown 文件。系统启动时会扫描这个目录,把所有符合条件的 .md 文件识别为 Skill。
加载策略:always 与 lazy
这是 Lite Skill 系统最核心的设计决策,也是它对「上下文是稀缺资源」这个原则的直接回应。
在之前那篇关于上下文管理的文章里,我详细讨论过 Anthropic Skills 的三阶段加载模型:发现阶段只加载元数据,激活阶段读取完整指令,执行阶段按需加载引用文件。YOLO 的实现把这个模型简化成了两档:
always 模式:技能的完整正文在每次对话开始时就被注入到 system prompt 里。模型不需要主动请求,这些内容始终存在于上下文中。适用于那些「每次对话都大概率用到」的基础性技能,比如输出格式规范。代价是 token 成本固定增加,所以 always 技能不宜太多,内容也不宜太长。
lazy 模式:系统只把技能的 id、name、description 注入到 system prompt 的 <available_skills> 区块里。当模型决定需要某个 lazy 技能时,它会产出一个 open_skill 的工具调用,参数是技能的 id 或 name(至少提供一个)。这个调用走的是标准的工具执行链路:模型产出 tool call → loop worker 进入 tool phase → 工具网关做权限检查 → 路由到本地工具执行器 → 读取技能文件 → 返回完整正文。
返回的内容会作为工具执行结果回写到消息列表里,模型在下一轮推理时就能看到完整的技能指令了。从模型的视角看,这和调用任何其他工具没有区别:它请求了一份资料,系统返回了资料内容,然后它基于这些内容继续工作。
用一个具体的例子来说明这两档的区别。假设你有 10 个 Skill,1 个是 always,9 个是 lazy:
- 对话开始时,system prompt 里包含:1 个 always 技能的完整正文(假设 2000 tokens)+ 9 个 lazy 技能的元数据摘要(假设每个 50 tokens,共 450 tokens)。总上下文开销约 2450 tokens。
- 如果把 10 个全设成 always:上下文开销变成 20000 tokens,是前者的 8 倍多。而其中大部分信息在当前对话中根本用不上。
- 如果用户在对话中提到了「帮我做周计划」,模型会从元数据里识别出
weekly-work-plan这个 Skill 与当前任务相关,调用open_skill拉取完整内容,然后按照里面的指令来执行。
这就是「元数据常驻 + 正文延迟加载」的实际效果:模型始终知道自己有哪些能力可用,但只在真正需要时才付出完整的上下文成本。
权限控制:谁能加载什么
Skill 系统的权限设计是一个「双层门禁」结构:
第一层:全局禁用。在插件设置里可以把某些 Skill 加入禁用列表,被禁用的 Skill 对所有 Assistant 都不可见,从元数据注入和工具调用两个维度同时屏蔽。
第二层:Assistant 级偏好。每个 Assistant 可以单独配置每个 Skill 的启用状态和加载模式。比如你的「学术写作」Assistant 可以启用 citation-format 技能并设为 always,而「日常闲聊」Assistant 则完全不加载这个技能。
两层叠加的优先级是:全局禁用 > Assistant 配置。也就是说,全局禁了的技能,不管 Assistant 怎么设置都不会生效。
在工具调用层面还有一道参数级的校验:即使 open_skill 工具本身可用,模型传入的 id 或 name 也必须命中当前 Assistant 的允许集合,否则调用会被拒绝。这防止了模型通过猜测 id 来加载未授权的技能。比较细节在允许集合的匹配统一做了小写转换,避免大小写差异导致的误判。
这套权限设计的出发点和工具网关是一样的:能力开放但边界可控。用户能精细地管理每个 Assistant 的技能装备,模型不会越权加载不该看到的东西。
四、未来展望
Agent Loop 和 Lite Skills 在 1.5.1 落地之后,YOLO 的 AI 能力算是有了一个能跑起来的底座。但「能跑起来」和「跑得好」之间还有不短的距离,接下来要做的事情大致分三个方向。
首先是工具调用的稳定性与体验。坦率地说,当前版本的工具调用在大多数场景下能正常工作,但还没到「闭着眼睛信任它」的程度。不同模型对 tool call 的格式遵从度参差不齐,有些模型偶尔会产出格式不完整的调用、或者在不该调工具的时候强行调一个。这些边界情况目前靠兜底逻辑在兜,但兜底终究是兜底,不是根治。后续迭代会持续打磨这一块:更精准的错误恢复策略、更清晰的工具执行反馈、以及用户侧更直观的状态展示。目标是让工具调用这件事对用户来说足够透明、足够可预期,而不是一个「大部分时候好使、偶尔抽风」的黑箱。
然后是搜索能力的重构。下一个大版本更新会重点强化搜索工具的效果。现有的 RAG 系统在 Smart Composer 时代就搭好了,当时的设计假设和现在的实际使用方式之间已经积累了不少偏差,是时候做一轮重构了。搜索是 Agent 在知识库场景里最核心的能力之一,模型再聪明,如果检索环节召回的内容不准、不全,后面的推理和操作就是在沙子上盖楼。这次重构的目标是让 Agent 在面对用户的模糊查询时,能更可靠地找到真正相关的内容,而不是返回一堆「关键词命中但语义无关」的结果。
最后,也是更长远的方向:Agent 模块会成为 YOLO 未来所有 AI 能力的基座。现在 Agent Loop + 工具层 + Lite Skills 这套组合已经证明了一件事:给模型一组工具和一套指令,它就能在 Obsidian vault 里完成相当复杂的任务。这个能力不应该被锁死在聊天窗口里。基于这个基座,后续会探索一些更有意思的形态,比如 AI 白板,让模型能在画布上组织和关联信息;比如全新的学习模式,让 Agent 根据你的笔记库内容主动生成复习计划、提出问题、构建知识图谱、帮你制作 anki 卡片和出题刷题。这些功能听起来跨度很大,但底层都是同一套东西:Agent 读取上下文、调用工具、按照 Skill 指令执行任务。差异只在于上层的交互形态和编排方式。
具体能做成什么样,做到什么程度,现在说太多都是画饼。但基座已经在了,剩下的就是在上面一层一层搭。请期待。
最后的最后,YOLO 是一个开源项目,它的上限取决于社区的参与度。
如果你在使用过程中遇到了 bug、发现了不合理的设计、或者觉得某个场景应该被支持但现在还没有,欢迎到 GitHub 上提 issue。如果可以的话,非常感谢大家可以提 PR。issue 告诉我「这里有个问题/需求」,PR 告诉我「这里有个问题/需求,而且我已经修/实现好了」。不用担心改动太小,修一个 typo、补一条边界处理、做一下 i18n 工作,都是实打实的贡献。一个人能搭出基座,但只有社区能把它变成真正好用的东西。
我们下次更新日志再见!