
上篇博客我们回顾了Minimax-01系列模型在传统Transformer的Attention机制上做的创新,实现了非常强劲可观的超长上下文外推能力,那么本篇将聚焦于 DeepSeek 的最新进展,深入分析其发布的 DeepSeek V3 和 DeepSeek R1 技术报告,探讨这些模型在架构设计、训练策略以及推理能力等方面的特点与创新。
DeepSeek V3 是一个强大的混合专家(MoE)语言模型,总参数量达到 6710 亿,每个 token 激活 370 亿参数。为了实现高效推理和经济高效的训练,DeepSeek V3 采用了多头潜在注意力(MLA)和 DeepSeekMoE 架构,这些技术在 DeepSeek V2 中已得到充分验证。此外,DeepSeek V3 开创性地采用了无辅助损失的负载均衡策略,并设定了多 token 预测训练目标,以增强模型性能。
DeepSeek R1 则展示了通过强化学习(RL)提升大型语言模型(LLM)推理能力的有效性。研究表明,即使不使用监督微调(SFT)作为冷启动,通过大规模强化学习也能显著提升推理能力。此外,加入少量冷启动数据可以进一步提升性能。
NOTE本篇是「模型考古学」系列的最后一篇。接下来的一段时间内我将转向宏观经济层面,重点关注以美联储为代表的中央银行政策工具与宏观经济指标的互动逻辑。同时,也可能会不定期分享一些关于图形渲染与 AI 超分技术的研究。 如果兴致来了可能也会写一些刑法相关的法学研究()
DeepSeek V3:强劲且性价比极高的通用基座模型
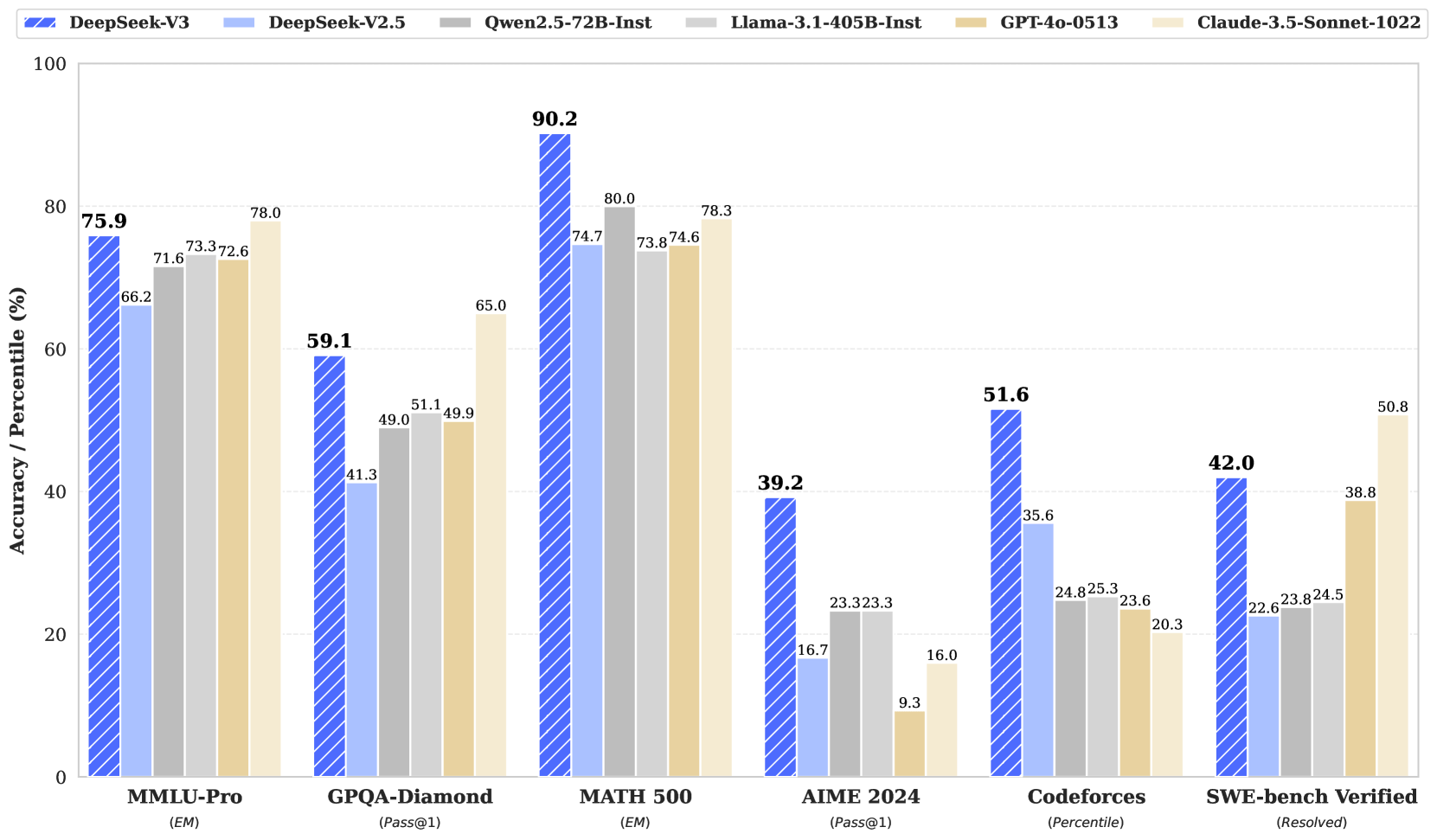
老规矩,先看看模型性能跑分:
前置知识(1):消融实验
“消融实验”(Ablation Study)是机器学习和深度学习研究中一种非常常见且重要的实验方法,主要用于回答这个问题:
模型中某个组件、机制或设计,究竟有没有用?
想象你在造一台复杂的机器,比如一辆电动车:
- 它有电池、马达、刹车系统、辅助仪表盘等多个模块。
- 如果你想知道“仪表盘”是否对整体性能有帮助,你就可以:
- 拿掉仪表盘
- 看看车还能不能正常跑,速度快不快,操控好不好
这就是“消融实验”的基本思想。
在深度学习中也一样:模型可能包含很多设计,比如多头注意力、位置编码、门控机制、预归一化等等。你要想知道某一项设计是否真的贡献了性能,就可以通过“删掉它”,再观察性能变化。
1.正式定义
消融实验是指在保留其他部分不变的前提下,有意识地移除模型中的某个模块、机制或超参数设置,并比较性能差异,从而验证该部分的有效性。
常用于:
- 验证新提出的模块是否真的带来提升
- 分析多种设计选择中哪个最优
- 给模型结构的设计决策提供依据
2.举例
比如 DeepSeek-V3 中使用了 MLA 注意力机制 和 FP8 训练。
要验证 MLA 是否有用,作者可能会做三组实验:
| 实验 | 使用 MLA | 使用标准注意力 | 结果 |
|---|---|---|---|
| baseline | ❌ | ✅ | perplexity = 4.1 |
| MLA-only | ✅ | ❌ | perplexity = 3.9 |
结论:加入 MLA 后性能提升,说明 MLA 是有效的。
再比如他们用了 Auxiliary-Loss-Free 的 MoE 路由,如果想验证“偏置项 ”是否真的起作用,可以做一个“去掉 bias 的版本”看结果是否变差,这也是一种消融实验。
常见的消融方式:
| 消融对象 | 举例 |
|---|---|
| 模型结构 | 拿掉残差连接 / 不用位置编码 |
| 模块设计 | 不用 MLA / 不用 MoE / 不加 gating bias |
| 训练策略 | 不用 warmup / 不加正则项 |
| 数据设置 | 去掉某类训练数据 / 不做预训练 |
| 精度控制 | 比较 FP8 / FP16 / BF16 |
前置知识(2):大模型精度格式
我们经常能看到例如FP16、BF16、FP8、INT8、INT4……
这些名字到底都是什么?
1.一张表格快速对比
| 格式 | 全称 | 位宽 | 数据结构 | 精度高低 | 常用于 | 是否支持训练 | 是否支持推理 | 硬件支持 |
|---|---|---|---|---|---|---|---|---|
| FP32 | Float32 | 32-bit | 1符号 + 8指数 + 23尾数 | 🔵 最高 | 传统训练/推理 | ✅ 稳定 | ✅ 准确 | 所有硬件 |
| FP16 | Float16 | 16-bit | 1符号 + 5指数 + 10尾数 | 🟡 中等 | 训练/推理 | ⚠️ 需配合技巧 | ✅ 主流 | A100/H100/3090等 |
| BF16 | Brain Floating Point 16 | 16-bit | 1符号 + 8指数 + 7尾数 | 🟡 中高 | 训练/推理 | ✅ 稳定 | ✅ 主流 | TPU/A100/H100等 |
| FP8 | Float8 | 8-bit | 1符号 + 5/4指数 + 2/3尾数 | 🟠 新兴 | 高效训练 | ✅(H100等) | 🚧 有待完善 | H100 专属 |
| INT8 | Integer 8-bit | 8-bit | 整数(非浮点) | 🔴 低 | 推理量化 | ❌ | ✅ 普遍 | 普遍支持 |
| INT4 | Integer 4-bit | 4-bit | 整数(非浮点) | 🔴 极低 | 极限推理 | ❌ | ✅ 受限 | 少数框架支持 |
2.这些格式的“结构”是怎么组成的?
浮点数格式(如 FP32、FP16、BF16、FP8) 一般由以下几部分组成:
- 符号位(Sign bit):决定正数还是负数(1 位);
- 指数位(Exponent):决定数值的范围(越多位,范围越大);
- 尾数位(Mantissa):决定数值的精度(越多位,小数越准确);
| 格式 | 总位数 | 指数位 | 尾数位 | 精度 vs 范围 | 特点 |
|---|---|---|---|---|---|
| FP32 | 32 | 8 | 23 | 精度高,范围广 | 训练和推理都没问题,就是显存太大 |
| FP16 | 16 | 5 | 10 | 精度中等,范围较小 | 显存省一半,适合训练推理 |
| BF16 | 16 | 8 | 7 | 精度低,范围大 | 精度略差,但动态范围和 FP32 一样,适合训练 |
| FP8 (E4M3 或 E5M2) | 8 | 4/5 | 3/2 | 精度和范围都低 | 靠精细策略才可训练 |
| INT8/INT4 | 8/4 | 0 | 全是定点整数 | 只支持离线静态值 | 仅用于推理压缩,不可训练 |
3.它们的主要用途是什么?
| 格式 | 用于训练? | 用于推理? | 优势 | 风险 |
|---|---|---|---|---|
| FP32 | ✅ 标准 | ✅ 标准 | 精度高、稳定 | 显存大,计算慢 |
| FP16 | ✅ 混合精度 | ✅ 高效推理 | 显存减半 | 对极端值不友好,易爆炸 |
| BF16 | ✅ 高稳定性训练 | ✅ 几乎原精度推理 | 动态范围大 | 小数精度差一些 |
| FP8 | ✅(配合技巧) | ✅(实验中) | 更节省显存 + 更高吞吐 | 容易溢出或数值不稳定 |
| INT8 | ❌ | ✅ 主流压缩 | 高压缩比,运行快 | 精度有一定损失 |
| INT4 | ❌ | ✅ 极致压缩 | 显存压缩最高 | 精度容易严重下降 |
4.精度格式的核心区别:
(1)数值表示能力(精度 + 范围)
- FP32 > BF16 ≈ FP16 > FP8 ≫ INT8 > INT4
- 训练需要高范围 & 高精度(FP32 / BF16);
- 推理只要保住前向结果基本不变就行(INT8 / INT4 够用)。
(2)显存占用
- 32bit → 16bit → 8bit → 4bit,显存逐级减半;
- FP8 训练相比 FP16 可以进一步减少 43% 显存,INT4 推理则可以压缩到 1/8。
(3)数值稳定性 vs 兼容性
- FP16 在一些早期 GPU(如 A100)上广泛支持;
- BF16 动态范围广,在 TPU、H100 上支持良好;
- FP8 是 Hopper GPU 之后的新特性,框架支持尚在完善;
- INT4 是纯粹为了极致压缩做的近似计算,只适合推理。
最后,再用一张表格总结一下:
| 角色 | 精度 | 用途 | 关键词 |
|---|---|---|---|
| FP32 | 最高 | 标准训练/推理 | 经典、安全、显存贵 |
| BF16 | 范围大,精度适中 | 主流大模型训练格式 | Google力推、TPU专属 |
| FP16 | 精度还行 | 高效推理、训练 | 显存节省,稳定性一般 |
| FP8 | 极低精度 | 训练新宠 | Hopper专属、高速、易炸 |
| INT8 | 非浮点,近似值 | 推理压缩主力 | 快、省、略降精度 |
| INT4 | 超低精度 | 推理极限压缩 | 速度狂魔,可能降智 |
一、模型创新总览
架构层面
- MLA多头潜在注意力,大幅降低推理成本(这个其实ds v2就有了)
- 在ds v2高效架构的基础上,开创了一种无辅助损失的负载均衡策略,最大限度地减少因鼓励负载均衡而导致的性能下降
- 多令牌预测(MTP)⽬标,并证明其对模型性能有益。它还可以⽤于推测性解码以加速推理
预训练:追求终极训练效率
- FP8混合精度训练,首次在超大规模模型上验证了其有效性
- 通过算法、框架和硬件的协同设计,ds克服了跨节点 MoE 训练中的通信瓶颈,实现了近乎完全的计算通信重叠。这显著提⾼了ds的训练效率,降低了训练成本,使ds能够在不增加额外开销的情况下进⼀步扩⼤模型规模
- 极致的工程优化和降本增效
在预训练阶段,DS在14.8T的数据上训练了V3,预训练过程异常稳定,在整个训练过程中没有碰到任何不可恢复的损失峰值,也无需回滚。
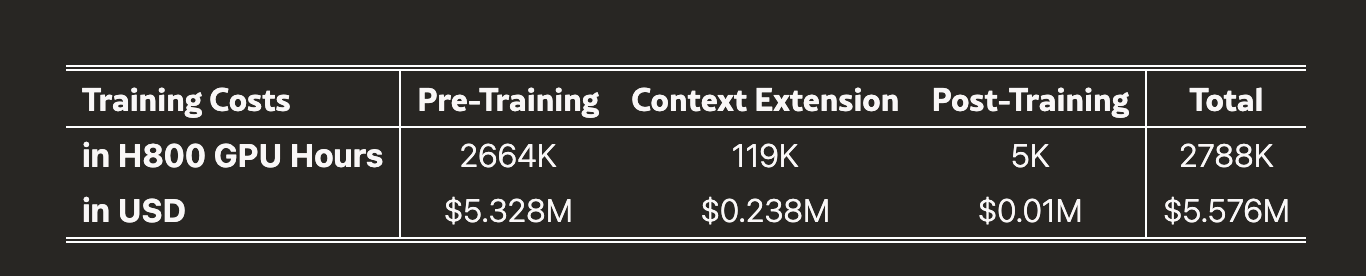
全部训练过程一共也就花了五百来万美元,令人感慨。
在预训练阶段,训练 DeepSeek-V3 每万亿 tokens 仅需 180K H800 GPU 小时。因此,在我们拥有 2048 个 H800 GPU 的集群上,训练时间仅需 3.7 天。我们的预训练阶段在不到两个月的时间内完成,消耗了 2664K GPU 小时。
结合上下文长度扩展所需的 119K GPU 小时和后训练所需的 5K GPU 小时,DeepSeek-V3 的完整训练总共消耗 2.788M GPU 小时。假设 H800 GPU 的租赁价格为每小时时 2 美元,我们的总训练成本仅为 557.6 万美元。
请注意,上述成本仅包括 DeepSeek-V3 的官方训练,不包括在架构、算法或数据上的前期研究和消融实验的成本。
后训练:从DeepSeek R1进行知识蒸馏
-
引入了一种创新方法,从长链思维(CoT)模型中锻炼推理能力,特别是从DeepSeek R1系列模型之一转化为标准的LLMs,特别是DeepSeek V3。DS将R1的验证和反思模式融入到DeepSeek V3,显著提升了其推理性能,同时也保持了对V3的输出风格和长度的控制。
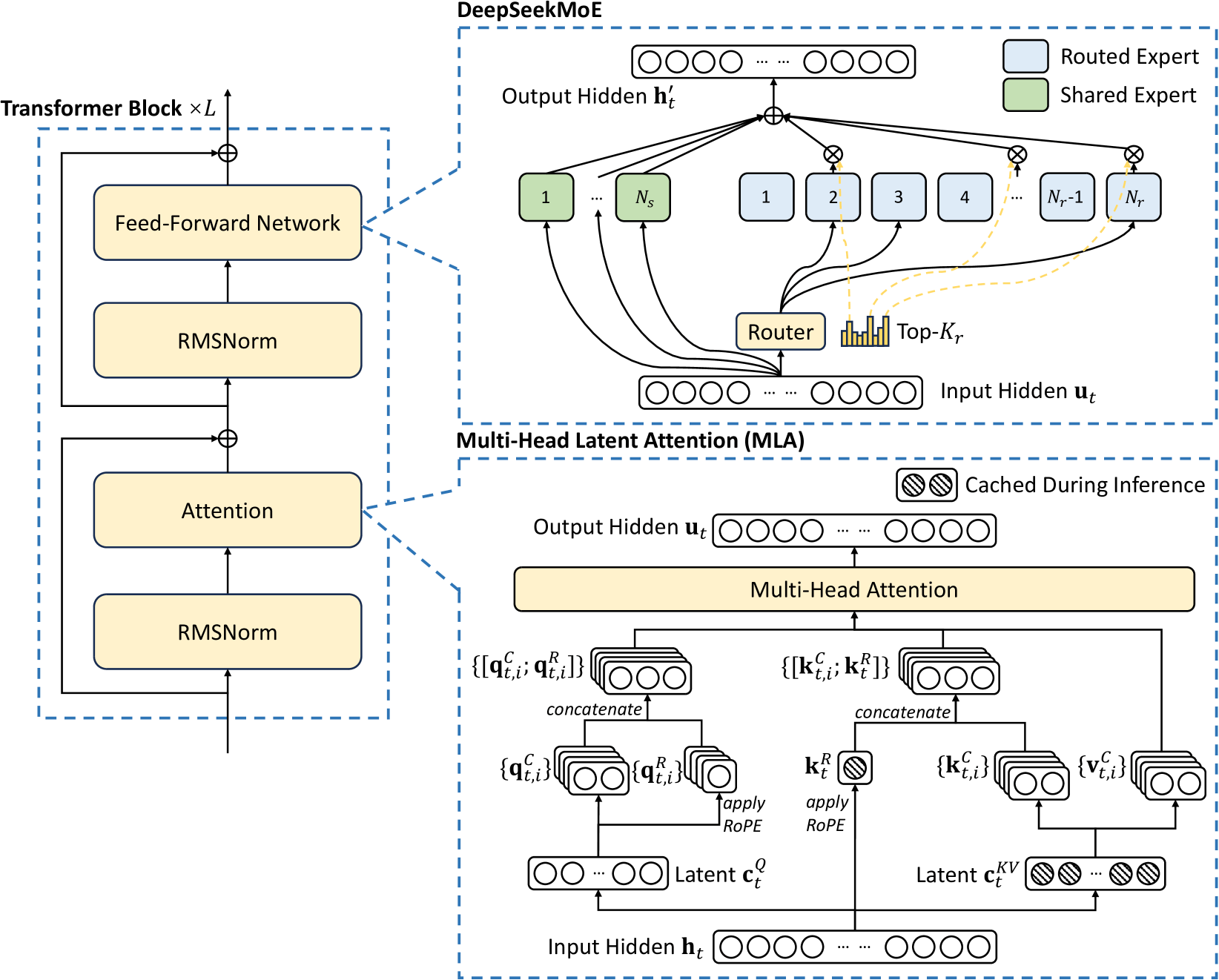
我们可以看到,和昨天的Minimax一样,Ds V3也是在Attention机制上做了大改良。DeepSeek V3的基本架构仍然在Transformer的框架内,为了实现高效推理和经济高效的训练,DS V3还采用了MLA和DeepSeek MoE,这二者的含金量在DS V2那里已经体现的非常明显了。
二、模型亮点:MLA多头潜在注意力
传统的多头注意力(Multi-Head Attention)最初就是在传统的Transformer架构(源自《Attention Is All You Need》, Vaswani 等人,2017 年)中提出的。它是 Transformer 中最核心的组件之一。这一组件可以被视为并行的多组注意力(Self-Attention),从而让模型在同一层面上对输入序列的不同位置或不同特征进行关注。多头注意力可以让模型在多个“视角”下去看输入序列,提高了对复杂关联关系的捕捉能力。
在标准的多头注意力中,我们通常会对输入向量 (对应第t个token,在某一层的隐状态)分别投影得到 矩阵,再将 与 做点积计算注意力分数,并基于分数加权求和得到输出向量。
- 设总的嵌入维度为 ,注意力头数为 ,每个头的维度为
- 对于训练大模型或做推理时,“KV 缓存”所占的空间往往非常可观。也就是说,在自回归生成推理时,需要保存大量的 和 (对所有已生成的token)的中间表示,以便后续计算新的注意力分数。
为什么DS要专门在这方面进行工程创新?
这是因为随着模型规模变大,我们的Attention注意力机制需要储存和计算的中间结果(尤其是 Key 和 Value,也就是常说的 KV 缓存)会爆炸式增长。这不仅导致显存压力巨大,也会影响推理时的速度。
MLA(Multi-Head Latent Attention)就是为了解决这个痛点而生的一种低秩压缩思路:它以较低维度的“潜表示(Latent Representation)”来替代原本的高维 Key/Value,极大地减少 KV 缓存需要的内存空间,并且在保持模型性能的同时降低推理或训练的成本。
MLA的核心思路:先压缩,再缓存
Step 1.压缩 Key/Value(减少推理时的 KV 缓存)
在传统的多头注意力中,每一步生成都要把 Key 和 Value 以相对高的维度保存下来,以便后续进行注意力计算。MLA 则提出了一个巧妙的两步走:
- Down-Projection
把输入隐藏向量(维度 )先映射到一个更小的维度 (),得到一个潜表示 。
- Up-Projection
当需要计算注意力时,再把这个潜表示用相应的投影矩阵还原回多头所需的 Key、Value 维度。
Step 2. 压缩 Query(节省训练时的激活内存)
在训练时,除了存储 KV,计算注意力的中间激活也非常占空间。MLA 还对 Query 做了类似的低秩压缩——先将降到一个小维度,再投影回原本多头空间。这样,同样能够减少反向传播时的激活开销。
MLA 中还强调了相对位置编码(RoPE, Rotary Position Embedding)的重要性。论文里会先对输入做一次 RoPE,然后与压缩后的 Key 或 Query 做拼接,让模型既能享受到低秩带来的内存优势,又能保留相对位置信息,提高注意力对序列顺序的理解能力。
总结一下MLA的优势:
- 显存占用要求大幅下降:推理时需要缓存的 KV 维度更小,大模型在长上下文推理时所需的内存压力小了许多。
- 训练内存也能节省:Query 的低秩投影让激活量减少,进而让训练时的显存开销降低。
- 模型性能几乎不受影响:如果下投影/上投影矩阵设计得当,MLA 在保持或近似保持原有性能的前提下,带来了巨大的内存收益。
MLA(Multi-Head Latent Attention) 简单来说就是给多头注意力配上一层“低秩眼镜”——它让 Key、Value(甚至 Query)在一个更小的维度里先“缩身”,再在需要注意力计算时“拉伸”回去。这种低秩操作减少了要缓存和计算的量,帮我们大幅降低显存/内存需求,同时性能上几乎与传统多头注意力相当。
三、无辅助损失负载均衡的DeepSeek MoE
1.MoE历史回顾与DS改进
MoE的历史还得追溯到1991年的论文《Adaptive Mixtures of Local Experts》,出自Geoffrey Hinton和Michael I. Jordan两人之手。虽然这个概念1988年就有了,但大部分的科研论文认为还是这篇论文奠定了MoE的基础。
而大模型时代开启之后最早采用MoE架构的模型应该是GPT4,发布于2023年3月,当时是George Hotz爆料GPT4是8×220B模型,让MoE架构第一次进入到大众的视野中。2023年12月,Mistral-8×7B发布,是全球第一个开源的MoE商用模型。
DeepSeekMoE 则在常规的 GShard/ Switch Transformer 等 MoE 结构基础上,做了以下重要改进:
- 更细粒度的专家:而不是每一层只有少量巨大的专家,DeepSeekMoE 将专家拆成更多、更小的单元以提升并行度、充分利用算力。
- 共享专家(Shared Expert)与路由专家(Routed Expert)并存:部分专家(“共享专家”)不依赖 token 的路由选择,所有 token 都会经过该专家;另一些则根据路由器的打分来决定是否被激活。
- Top-K 路由:每个 token 会选取得分最高的 个路由专家参与计算;每个 token 的负载只会分配到有限个专家上,以防止过大的通信与计算开销。
2.负载均衡问题与传统的“辅助损失”方法
在标准的 Mixture-of-Experts(MoE)模型中,Feed-Forward Network(FFN)往往被拆分成多个“专家(Expert)”,由门控函数(Router 或 Gating)决定每个 token 会被路由给哪些专家,从而带来参数可扩展性和计算加速。
在 MoE 模型里,如果路由器的打分不平衡,有些专家可能收到过多 token,另一些则几乎“闲置”,称之为路由崩溃(Routing Collapse)。为了避免这种情况,过去常常在训练时引入辅助损失(Auxiliary Loss)(比如 Google Switch Transformer 的负熵正则化),鼓励模型把路由分数分散给更多专家,从而达到负载均衡。
但这种做法有一个明显缺点:辅助损失越强,模型的主任务性能就越可能被干扰。因为它相当于在主损失之外引入强力的正则项,可能破坏模型本来自然学到的高质量路由分布。
3.无需额外辅助损失的负载均衡策略(Auxiliary-Loss-Free Strategy)
为了兼顾“路由负载均衡”与“模型性能”,DeepSeek-V3 提出了一种无需额外辅助损失的负载均衡策略(Auxiliary-Loss-Free Strategy)。主要做法如下:
3.1 在路由打分中引入“偏置项”
- 对于每个路由专家 ,都会维护一个可训练或可动态更新的偏置 (Bias)
- token 要选 Top-K 专家时,用的不是原始分数直接排序,而是作为最终排序依据
- 如果某个专家在前一批训练样本中过载(被选中的 token 太多),就调小;反之,如果该专家“吃不饱”,就调大
- 通过这种动态调整偏置,系统会逐渐把一些 token 分流给那些负载较轻的专家,实现整体的负载均衡。
值得注意的是,真正用来计算专家输出加权的门控值 仍然是原始的 ,而不是 。也就是说,偏置只影响“被不被选中”,不会对已经选中的专家输出的加权造成直接干扰,从而尽量减小对模型原本学习的干扰。
3.2 具体的偏置更新规则
论文中采用一种简单直接的策略:
- 每个训练 step 或一定步数后,统计各专家在该 batch 内的被选取次数;
- 如果某专家的占比超过平均负载,就判定“过载”,相应地对该专家的 减去一个固定步长 ;
- 如果某专家的占比低于平均负载,就判定“欠载”,对该专家的 加上同样的步长 ;
- 称为 bias update speed,可以是一个小超参数(如 0.001)。
这样,过载的专家会渐渐拉低其路由排序打分,从而被选中的概率下降;欠载的专家则相反。
3.3 保留少量的“序列级别”辅助损失
- 另外,DeepSeek 还在训练时保留了一个极小的序列级别平衡损失(sequence-wise auxiliary loss),仅用于避免单条样本出现极端失衡——但它的权重非常低,以免影响主任务。
- 该损失并不像传统的 GShard/Switch 里那样对整个 batch 做很强的负熵约束,而只是保证在“单个序列”内部不要完全只选到少数几个专家。
通过这种“批量维度”或“序列维度”的松弛约束,再加上动态更新的 bias,实现了在大规模训练中保持负载平衡,而又不严重牺牲性能。
4.技术优点
这么做最主要的优点还是可以避免高强度辅助损失破坏主任务。之前的 MoE 常常发现,辅助损失系数一大就会明显影响收敛效果。现在这种做法只在路由决策层引入偏置,且只改变“被选与否”,对专家输出的加权几乎不插手,从而大幅减轻副作用。DS的动态调参机制在大规模MoE训练实践中表现稳定,可以维持长时间的负载健康,在论文实验中DS还观察到没有纯辅助损失的强干扰后,专家更容易在不同领域数据上出现“专业化”分工。
- 在保持整体高效训练和推理加速的同时,也获得了更灵活、更稳健的专家分布;
- 实验结果显示,这种方法往往能带来更好的模型精度/推断能力;
- 也为大规模 MoE 模型在分布式场景下提供了更优的稳定性和资源利用效率。
四、FP8训练
这部分解释研究起来有点太干了,总而言之就是受益于新的 Hopper GPU(H800 等) 上专门提供了 FP8 Tensor Core,以及对混合精度训练(TensorFloat-32、BF16、FP8)的多项优化,使得低精度可以真正大规模应用而不会拖慢速度。由此,DS团队成功地将 FP8 训练稳定地应用到超过百亿甚至千亿参数量级的模型上,大幅减少了显存占用,同时提高了训练速度,这是过去采用 BF16/FP16 无法进一步显著降低成本的一个新“突破口”。
1.为什么之前不常用“低精度”做大模型训练?
-
硬件限制:低精度训练(如 FP8)需要 GPU 硬件在核心计算单元(Tensor Core)上支持相应格式,并且有配套的高速量化/反量化操作。如果硬件不支持,就只能用软件仿真,效率会非常低,还可能要应对额外的数值不稳定性。
-
数值稳定性担忧:一旦精度再降低(从 16-bit 再到 8-bit),激活、梯度就很容易受离群值影响而产生严重的溢出或舍入误差——导致梯度爆炸或模型发散。过去很多实践经验表明,大模型里存在非常大的激活值、梯度值,直接用 8-bit 的浮点或定点数训练,往往极不稳定。
-
已有 BF16(或 FP16)普遍可用且稳定:在过去几年里,BF16 训练已经被各大框架、大模型实验证明较为稳妥,既保证了足够数值范围,又带来了比 FP32 小得多的内存占用和训练加速。开发者往往选择先用 BF16 做大规模模型,这样可以避免太多新的风险。
2.为啥DS能做到FP8训练
- 精细的量化策略:对激活、权重进行 tile-wise 或 block-wise 的分块缩放(scaling),而非一刀切的整张张量缩放;这样能够更好地对应激活中局部分布的不同,使得离群值不会破坏整体量化效果。
- 高精度累加(Accumulation):在做 8-bit Tensor Core 乘加(MMA)时,会把中间结果及时地在 CUDA Core 里用更高精度(如 FP32)进行部分累加,避免大量舍入误差。
- 保持部分关键操作的高精度:例如残差连接、归一化层、门控分数 (MoE gating) 等仍在更高精度(BF16/FP32)中计算,最大程度地保证训练稳定性。
- 支持更好的硬件:在新的 Hopper GPU(H800 等) 上专门提供了 FP8 Tensor Core,以及对混合精度训练(TensorFloat-32、BF16、FP8)的多项优化,使得低精度可以真正大规模应用而不会拖慢速度。
五、多Token预测评估(MTP技术)
1.在训练时多令牌预测,一次生成多个未来目标
传统的自回归预测方式(如 GPT 等模型)在解码时一次只能根据已生成的上下文预测下一个单一的令牌(token),然后再将新产生的令牌拼到上下文中,继续预测下一个,依次循环。
MTP(Multi-Token Prediction) 的想法是:在每个位置上,不仅预测下一个令牌,还同时并行预测再往后的第二个或更多个未来令牌。这样一来,模型在训练时就能得到更加丰富的训练信号,从而在推理阶段也可以进一步将这些一次性预测出的多个令牌作为备选,利用推测性解码来整体加速生成。
具体做法是:
- 主模型(Main Model) 依旧负责对下一个令牌进行标准的自回归预测;
- 若干个 MTP 模块(MTP Modules) 用来额外预测后续更多位置的令牌。例如当设置深度 时,每个 token 除了获得下一令牌的分布,还额外得到预测“第二个令牌”的分布。
- 使用多条交叉熵损失的平均值来训练,在不增加(或仅少量增加)推理参数量的前提下让模型获得“深度规划式”的预测能力。
推测性解码(speculative decoding) 的核心在于:如果模型一次能预测出多个“候选”令牌,那么下游的“鉴别/接受”机制可以迅速验证哪些令牌真正能够拼接到最终输出中,而不必等待模型一步步地自回归生成。简单来说,推测性解码更像一次性拿到了模型对“接下来的几个位置”整体的预测,再根据一定的规则或辅助判断来“验收”这些额外预测。只要这些额外预测通过了验收,系统就可以一次性把它们放入生成序列里,加快输出速度。
为此,DS在主模型之外新增了额外的 Transformer Block 和线性变换矩阵(投影层),它们与主模型的嵌入层和输出层共享参数或部分共享结构,使模型在一次前向过程中就能额外产生未来更多位置的预测分布
2.推理阶段如何利用MTP提升生成速度
训练完成后,模型可以直接 丢弃 这些 MTP 模块,仍像普通自回归那样一次只预测下一个令牌;或者也可以结合 推测性解码(speculative decoding) 的思路,把 MTP 模块附加到推理流程中,提高解码速度。作者强调:
“由于第二个令牌预测的接受率(acceptance rate)相当高,大约在 85%~90%,因此在推理过程中能够一次性批量采纳额外的预测,大大提升解码吞吐量,TPS(Tokens Per Second)相应可提高到 1.8 倍。”
这说明当 MTP 模块一次预测出 2 个令牌时,后验检查/鉴别机制发现其中绝大多数是符合上下文的正确令牌,从而可以跳过部分自回归步骤,整体减少了生成过程的迭代次数。
这套方法能够在 不显著牺牲预测质量 的前提下,显著提升大模型的推理效率,对大规模应用部署非常实用。论文中还提到如果不需要多令牌并行推理,也可以直接忽略或关闭 MTP 模块,单独使用主模型进行常规解码,保证兼容性与灵活性。
未来方向
最后,让我们看一下DS团队在V3论文里对未来的前瞻:
- 在训练和推理效率⽅面,我们⼒求实现对⽆限上下⽂⻓度的⾼效⽀持。此外,我们将尝试突破Transformer 的架构限制,从⽽推动其建模能⼒的边界。
NOTEMamba和线性注意力,启动!
- 我们将持续迭代训练数据的数量和质量,并探索整合更多训练信号来源,旨在推动数据在更⼴泛维度上的扩展。
- 我们将持续探索和迭代模型的深度思考能⼒,旨在通过扩展其推理⻓度和深度来增强其智能和问题解决能⼒。
- 我们将探索更全⾯和多维的模型评估⽅法,以防⽌在研究过程中过度优化固定基准测试,这可能会对模型能⼒产⽣误导性印象并影响我们的基础评估。
DeepSeek-R1:RL驱动、o1水平的开源推理模型
NOTE最伟大和出圈的一集
我已经懒得在这里介绍R1发布后的热度几何震撼几何了,直接看论文吧。
我们推出了第一代推理模型 DeepSeek-R1-Zero 和 DeepSeek-R1。
DeepSeek-R1-Zero 是一个通过大规模强化学习(RL)训练而成的模型,未经过监督微调(SFT)作为初步步骤,展示了卓越的推理能力。通过 RL,DeepSeek-R1-Zero 自然涌现出许多强大且有趣的推理行为。然而,它也面临诸如可读性差和语言混合等挑战。
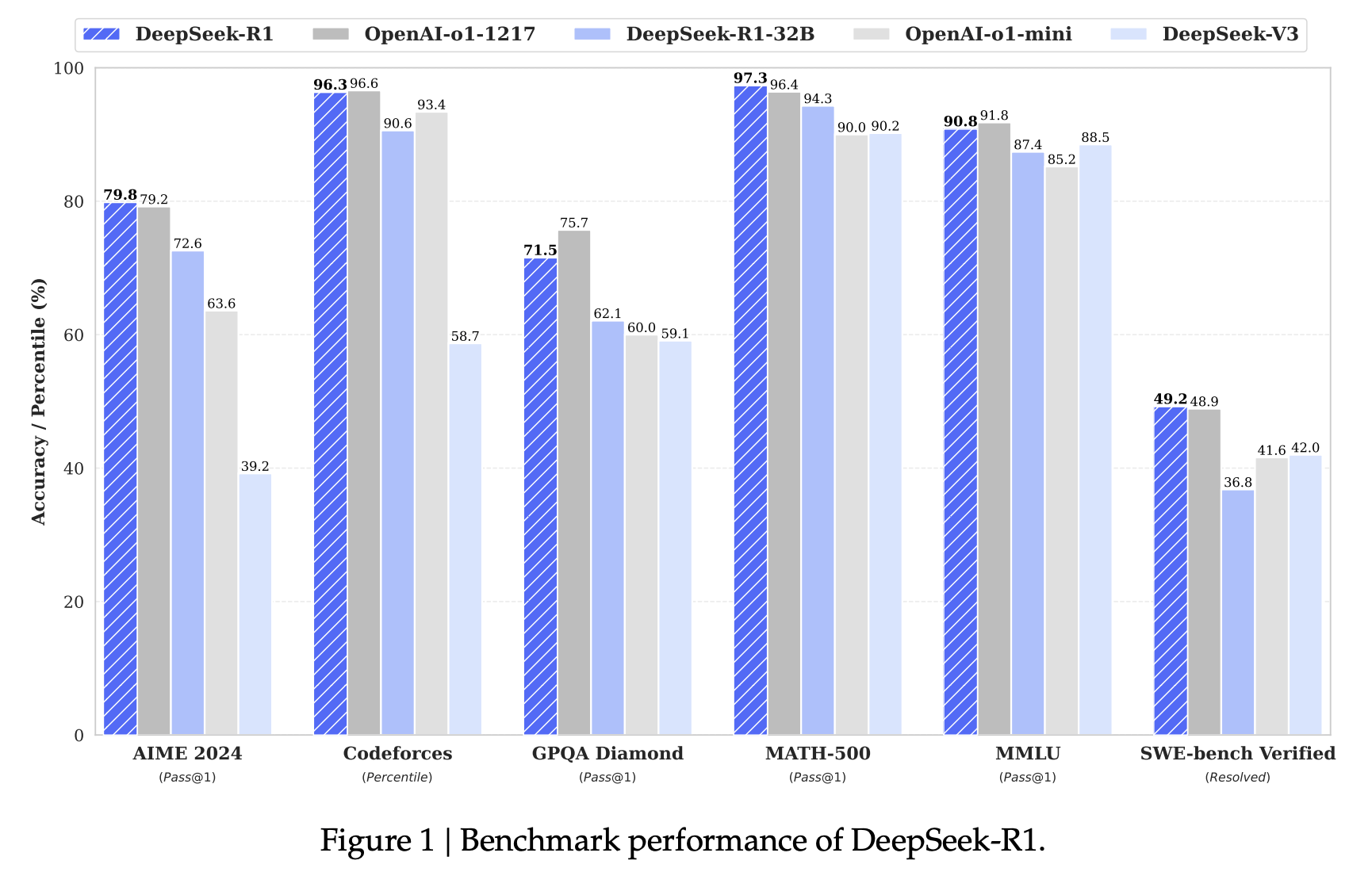
为了解决这些问题并进一步提升推理性能,我们推出了 DeepSeek-R1。该模型在 RL 之前引入了多阶段训练和冷启动数据。DeepSeek-R1 在推理任务上的表现与 OpenAI-o1-1217 相当。
为了支持研究社区,我们开源了以下内容:
- DeepSeek-R1-Zero
- DeepSeek-R1
- 基于 Qwen 和 Llama 从 DeepSeek-R1 蒸馏出的六个密集模型(1.5B、7B、8B、14B、32B、70B)
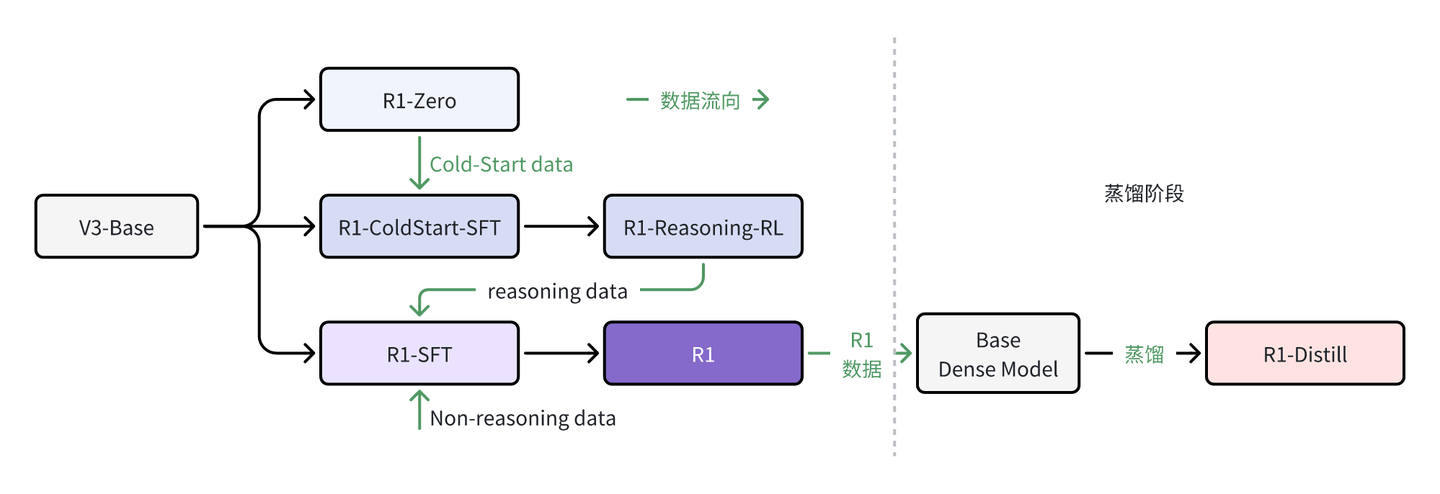
本次DeepSeek相当于发布了三个部分的模型:
- DeepSeek-R1-Zero:疯狂的CoT推理机器,无SFT纯RL训练,不管输出格式,解答不做summarization,阅读性差无格式
- DeepSeek-R1:带冷启动(Cold Start)SFT,然后做RL训练,控制输出格式,有summarization,是成熟的可直接部署的版本
- DeepSeek-R1-Distill:基于Qwen和Llama作为Base从R1数据蒸馏成小模型
整体流程:
一、研究贡献总结
1.为什么说DeepSeek-R1-Zero的重大进步是采用纯RL?
从现有文献和实践来看,传统的大模型往往需要先用一定量的监督数据(SFT,Supervised Fine-Tuning)“热身”,再进行强化学习(RL)阶段来进一步提升模型在推理、对齐等方面的能力。
在不少以往的做法中(例如常见的 PPO、RLFH 等训练流程),会先通过人工或已有模型注释的大规模数据对基模型进行有监督微调,一方面让模型学到更一致的回答风格与格式,另一方面将模型初步对齐到正确的解题思路与答题模式之上。之后再结合强化学习策略(往往利用训练的奖励模型或预先人工标注),做进一步的性能或对齐提升。
DeepSeek-R1-Zero 则跳过了这一步:它只基于一些“可度量正确性”的问题(如数学、编程)用规则或判题器给出奖励,完全通过强化学习便“生长”出了多步推理、自动反思等行为。这在一定程度上证明了只要合理地设计奖励函数和训练流程,模型可以通过大规模强化学习自发地“演化”出长链推理、反思(reflection)等复杂能力,而不一定要依赖先验的监督数据。
当然,DeepSeek-R1-Zero 在可读性等方面仍有一定缺陷(容易出现多语混杂、叙述不够流畅等),因此后续又在其基础上结合了少量冷启动数据(cold-start data)及多阶段强化学习,形成更好用、更平衡的 DeepSeek-R1 版本。
2.蒸馏:小模型也可以很强大
使用DeepSeek-R1生成的推理数据,DS对社区中广泛使用的几个密集模型进行了微调。
评估结果表明,提炼出的⼩型密集模型在基准测试中表现非常出色。DeepSeekR1-Distill-Qwen-7B 在 AIME 2024 上达到了 55.5%,超过了 QwQ-32B-Preview。此外,DeepSeek-R1-Distill-Qwen-32B 在 AIME 2024 上得分为 72.6%,在 MATH-500 上得分为 94.3%,在 LiveCodeBench 上得分为 57.2%。这些结果显著优于之前的开源模型,并与 o1-mini 相当。DS 向社区开源了基于 Qwen2.5 和 Llama3 系列的 1.5B、7B、8B、14B、32B 和 70B 的checkpoint。
3.向全世界开源了一款o1级别性能的、商用级别的、极高性价比的、中国产的推理模型
具体跑分这里就不写了。除了之前大家都默认的数理代码能力之外,DeepSeek R1出圈的重要甚至主要原因还在于R1的文学创作能力非常强,当时确实实实在在的惊艳到我了,给全国人民送了个大礼。
二、DeepSeek-R1-Zero:在基础模型上进行强化学习
之前的研究表明RL在推理任务中表现出显著的有效性,但这些工作严重依赖于人类监督数据,而这种数据的搜集非常耗时耗力,需要大量的数据劳工苦力。因此,DS探索了LLMs在没有监督数据下发展推理能力的潜力,重点关注模型通过纯RL过程中的自我进化。
1.基座模型与强化学习算法
DS选取了一个预训练好的大模型(DeepSeek-V3-Base)作为初始的基座模型,采用一种名为 Group Relative Policy Optimization(GRPO)的方法,该算法与 PPO 类似,但不需要单独的价值网络。
对于每个训练样本,DS会从旧策略采样一组输出,然后计算每个输出的奖励,与组内其他输出的奖励进行对比形成优势(advantage),最后用带有裁剪(clipping)的目标函数来更新策略模型。这样既简化了计算开销,也能在大规模 RL 训练中保持稳定。
2.奖励设计:基于“正确性+格式”
- 正确性奖励(accuracy reward):针对有明确判分标准的问题(如数学、编程),用规则(例如数学答案可直接比对,编程通过编译测试用例)来判断输出是否正确,并给予相应的奖励或惩罚。
- 格式奖励(format reward):要求模型在回答时先输出推理过程(用
标签包裹),再输出答案(用 标签包裹)。如果模型遵守这一格式,就会获得额外的正奖励。
模型训练对话模板如下:
A conversation between User and Assistant.The user asks a question, and the Assistant solves it.The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.The reasoning process and answer are enclosed within <think> </think> and <answer> </answer>, respectively.
User: <prompt>Assistant:- 模型输出时,必须先写下完整推理(
… ),再给出最终答案(… )。如果答案被规则判定为正确,同时格式合规,则累加奖励。
对于数理题这种有确定答案地场景,通过匹配答案正确性就能获得奖励,例如:
question: find the minimal value of x^2 - 4x + 1 = 0
……
Answer:
正确答案是 -3,那么可以通过规则匹配上就可以得到奖励1,匹配不上为奖励-1,特别的要处理1/2和0.5这种同值不同形式的匹配。
-
通过这种大规模、持续迭代的 RL 训练,让模型不断学会更长、更完整的推理,并提升准确率。
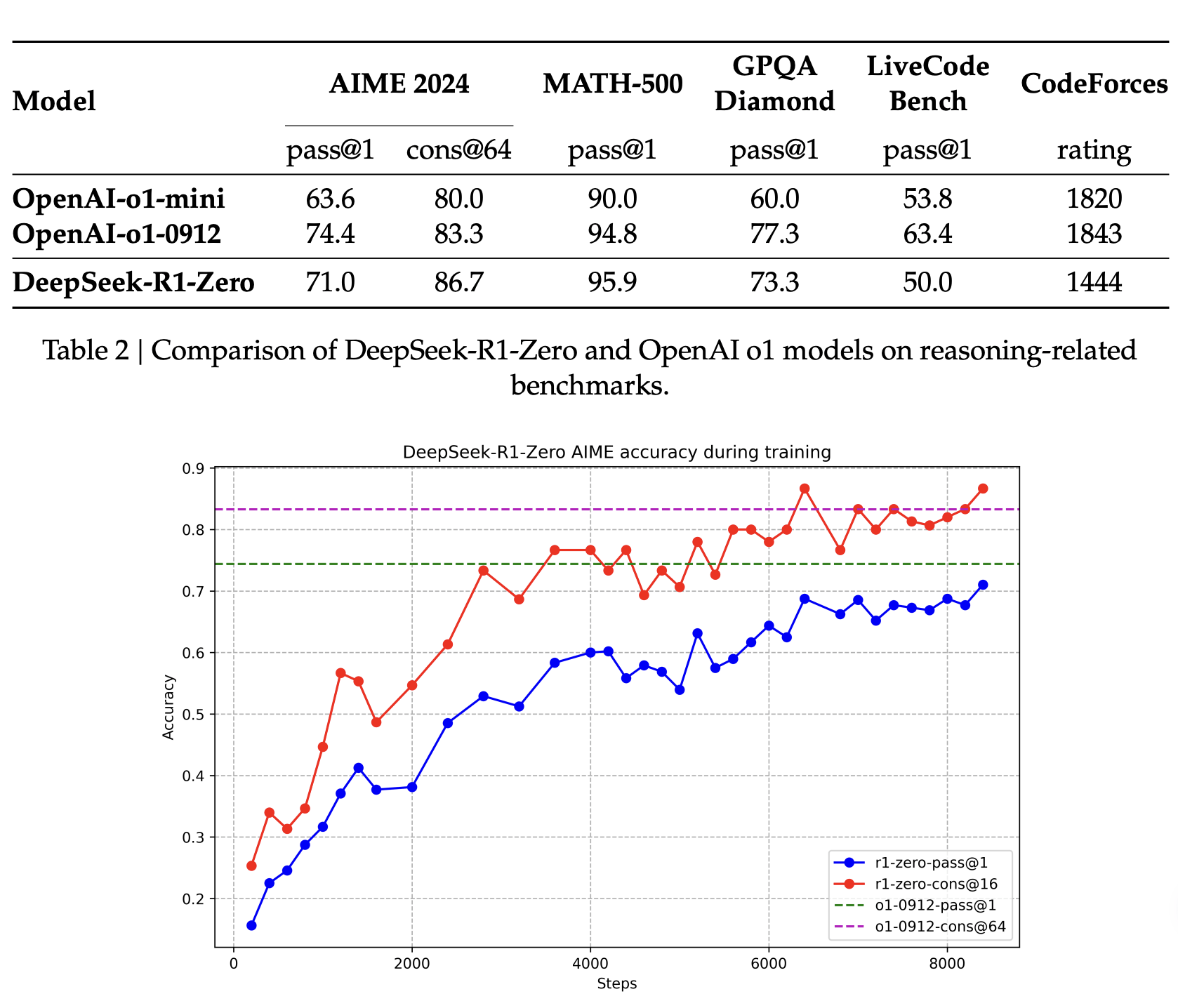
可以看到,随着RL的推进,DeepSeek-R1-Zero表现出稳定且一致的性能提升。
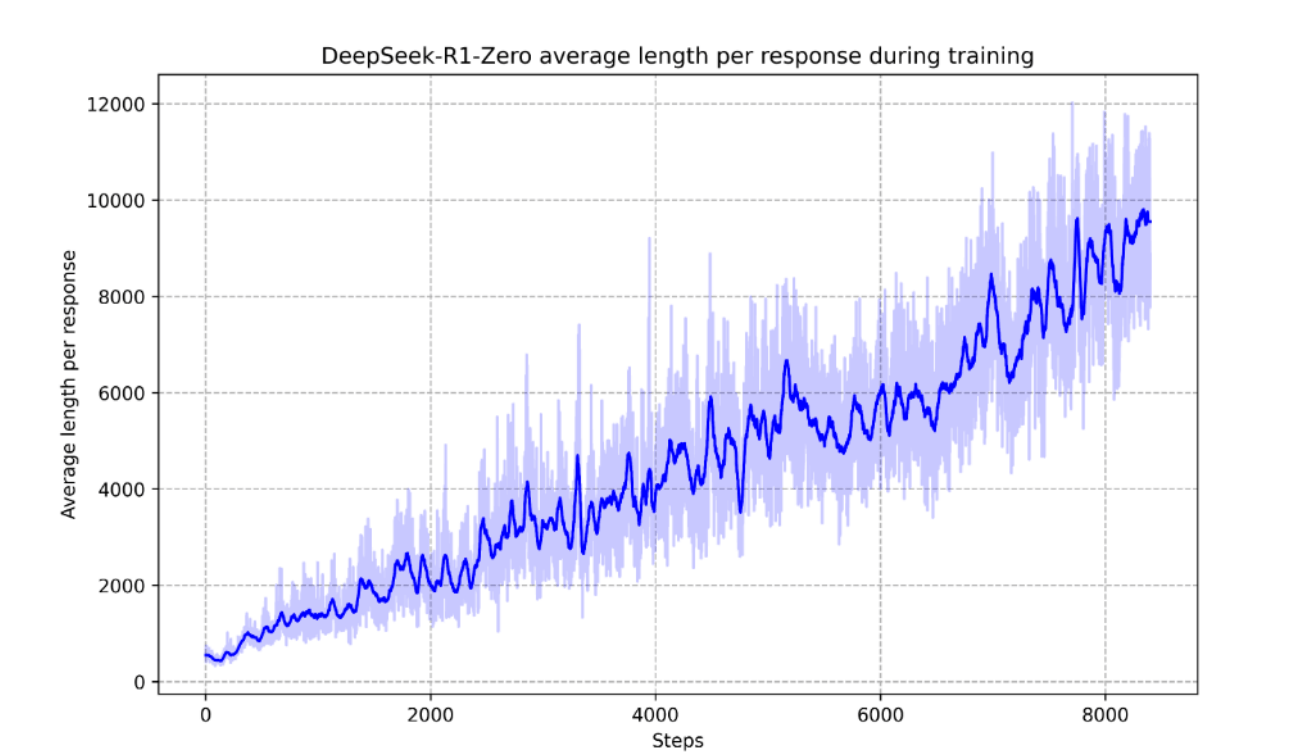
图为DeepSeek-R1-Zero在RL过程中训练集上的平均响应长度。可以看出DeepSeek-R1-Zero自然地学会了通过更多的思考时间来解决推理任务。
在整个训练过程中,模型的改进并非来自外部调整,而是源于内部的内在发展。DeepSeek-R1-Zero 通过利用扩展的测试时间计算,自然地获得了解决日益复杂推理任务的能力。这种计算范围从生成数百到数千个推理标记,使模型能够更深入地探索和完善其思维过程。
这种自我进化最显著的一个方面是,随着测试时间计算的增加,复杂行为的出现。例如,模型会进行反思——即重新审视和评估其先前的步骤——并探索解决问题的替代方法。这些行为并非明确编程,而是模型与强化学习环境交互的结果。这种自发的发展显著增强了 DeepSeek-R1-Zero 的推理能力,使其能够更高效、更准确地应对更具挑战性的任务。
3.自发涌现的长链推理与反思
DeepSeek-R1-Zero在训练中并没有显式地被人工示例教导要“写冗长推理”或“要进行自我反思”,而是通过准确性与格式的奖励信号,自发产生了长链推理与多次自我检查、反思(reflection)等复杂行为。
训练进行到中期时,模型在推理过程中可能会出现“突然意识到自己推理有误”然后改写推理的“aha moment”,这在纯 RL 场景下非常有意思。aha moment强调了RL的力量和美感:我们不需要明确地教导模型如何解决问题,而是需要简单地为其提供正确的激励,模型就会自主发展出高级的问题解决策略。

三、DeepSeek-R1:冷启动的强化学习
DS研究团队在观察到R1-Zero的显著成果和局限性之后,提出了两个问题:
- 通过引入少量高质量数据作为冷启动,能否进一步提升推理性能或加速收敛?
- 如何训练一个用户友好的模型,不仅能生成清晰连贯的思维链(CoT),还能展示强大的通用能力?
为此,DS开始了R1的训练。
1.冷启动-少量SFT
为了防止从基础模型开始的RL训练出现太多的不稳定因素,训练团队先使用少量精心挑选并带有详细推理过程的监督数据(SFT数据)来对基座模型进行一次初步微调,让模型拥有一个更好的起点。
简单概括来说,冷启动数据大多是一些带有详细推理步骤的题目(如数学推理、编程问题),由人工或已有模型先生成较高质量的示例,让 DeepSeek-V3-Base 先学到合适的“写作/推理风格”、清晰的答案格式以及基础的解题思路。随后再通过强化学习去“放大”这些推理能力,进一步提升准确率与推理深度。这样做不但能加速模型从无到有的推理能力构建,而且还能保证最终模型在语言流畅度、格式可读性方面有更出色的表现。
与 DeepSeek-R1-Zero 完全跳过 SFT、直接用 RL 训练基模型相比,冷启动的目的是帮助模型预先“学会”一些人类可读的推理格式和初步思路,从而在后续的大规模 RL 中更快、更稳定地收敛,并且避免出现多种语言混杂、可读性差等问题。
可读性:
DeepSeek-R1-Zero 的一个关键限制是其内容通常不适合阅读。响应可能混合多种语言,或缺乏 Markdown 格式来突出显示答案。相比之下,在为 DeepSeek-R1 创建冷启动数据时,研究团队设计了一种可读的模式,包括在每次响应的末尾添加摘要,并过滤掉对读者不友好的响应。此处,输出格式定义为
|special_token|<推理过程>|special_token|<摘要>,其中推理过程是查询的 CoT,摘要用于总结推理结果。潜力:
通过精心设计带有人类先验的冷启动数据模式,研究团队观察到相较于 DeepSeek-R1-Zero 的更好性能,他们相信,迭代训练是推理模型的更优方式。
2.面向推理的强化学习 RL
在冷启动数据上对 DeepSeek-V3-Base 进行微调后,研究团队采用了与 DeepSeek-R1-Zero 相同的大规模强化学习训练过程。这一阶段的重点是增强模型的推理能力,特别是在编码、数学、科学和逻辑推理等推理密集型任务中,这些任务涉及具有明确解决方案的明确定义的问题。
在训练过程中,研究团队观察到 CoT 经常出现语言混合现象,尤其是在 RL 提示涉及多种语言时。为了缓解语言混合问题,研究团队在 RL 训练中引入了语言一致性奖励,该奖励计算为 CoT 中目标语言单词的比例。尽管消融实验表明这种调整可能导致模型性能略有下降,但这种奖励符合人类偏好,使其更具可读性。
最后,研究团队通过直接相加将推理任务的准确性和语言一致性奖励结合起来,形成最终奖励。然后,研究团队在微调后的模型上应用 RL 训练,直到其在推理任务上达到收敛。
3.拒绝采样阶段(收集整理SFT数据)
在RL阶段基本收敛之后,DS会基于当前的RL检查点来生成一批新的监督微调SFT数据,用于下一阶段的正式SFT训练。和初始“冷启动”阶段只面向推理任务不同,这一次他们会纳入更多不同任务类型的数据,进而增强模型在写作、角色扮演、问答、翻译等通用场景下的能力,此过程包含以下两部分:
3.1 生成推理数据:拒绝采样
首先,“拒绝采样”(rejection sampling)指的是针对同一个提示多次采样,让已训练(或正在训练)中的模型对同一个问题/提示生成多条不同的回答。生成后,研究团队将基于质量标准筛选输出,对这些候选输出进行自动或人工的质量评估,凡是未通过评估标准(例如判定错误、格式混乱、或不符预期)的回答会被“拒绝”掉;只有通过评估、被判定为正确或高质量的回答才会被“接受”并保留下来,用作下一轮监督微调(SFT)的训练数据。
之所以要做拒绝采样,是因为即使经过强化学习后的检查点,也难免会产生一些错误或较低质量的回答。通过一次性采样多个候选并只保留“正确/优质”回答,就可以自动构造出更高质量的 SFT 数据,减少人工标注量,同时让模型在后续训练中获得更精准的监督信号。
这一阶段采用基于规则的正确性判定(如判题器检查数学/编程题)、生成式奖励模型(将真实答案与模型预测输入 DeepSeek-V3 等模型对比打分)等手段。同时为了保证可读性,会过滤掉混合语言、过长段落、凌乱代码块等不符合预期的输出,最终只保留质量较高、答案正确的候选回答。
最终,他们将“被接受”的回答连同对应的提示(Prompt)一起,整理为标准的监督训练样本,包含完整的“问题-思维链-答案”结构。经过多次迭代的“拒绝采样”后,一共收集了约60万条与推理相关的训练样本。
3.2 扩充非推理数据
在此阶段还会纳入与推理无关的任务数据,以便提升模型在写作、对话、角色扮演、知识问答、翻译等更广泛场景下的实用性。
- 复用已有数据:从 DeepSeek-V3 的 SFT 数据集中,筛选出写作、问答、翻译等任务示例。对于部分任务(如较复杂的写作场景),可以引导模型产生一定的“思维链”帮助其构思;但对于简单问候类的请求,如“你好”,就不再强制输出 CoT。
- 补充新的通用场景:补充一些额外的数据源,如带有多轮对话、角色扮演、自我认知等场景,保证模型在日常交流及复杂对话中的表现更自然。
最终,他们搜集了大约 20 万个与推理⽆关的训练样本。
4.监督微调 正式SFT训练
综合上述推理与非推理数据,共计约 80 万条训练样本,构成一个高质量、覆盖多领域的 SFT 数据集。将该数据集用于对 DeepSeek-V3-Base 模型进行 2 个 Epoch 左右的监督微调(SFT):
- 对齐模型风格:通过监督方式,让模型在推理格式、回复风格、对话礼仪、内容连贯等方面更加统一、自然。
- 提升多场景能力:既强化了模型在数学、编程、逻辑推理上的正确率,又扩充了模型在写作、问答、对话、翻译等通用场景的实用性。
在完成这一步后,模型基本具备了较完善的回答形式和可读性,并能在多类任务中提供较高水平的答复。随后结合更多场景的 RL 训练,可以进一步增强模型的对齐效果与安全性,使得 DeepSeek-R1 系列在推理能力和通用应用之间达到更好的平衡。
四、蒸馏:赋予小模型推理能力
在强化学习阶段得到的强大推理模型 DeepSeek-R1,可进一步作为“教师模型”为小模型进行蒸馏(Distillation),从而让小模型也能具备相当程度的高阶推理能力。其核心思路是:从教师模型中采样出丰富、高质量的推理数据,再用这些数据对小模型做有监督的微调(SFT),就能让小模型学到教师模型在思维链(Chain-of-Thought)、答案精准度等方面的优点。
1.蒸馏流程概览
教师模型:选定已经完成多轮强化学习并表现出优异推理能力的 DeepSeek-R1 checkpoint,通过它在大量、多类型的推理场景中进行推理采样,得到以 <think>…</think> 形式呈现的思维链 + <answer>…</answer> 最终答案。
之后,进行数据筛选,类似拒绝采样(Rejection Sampling)的思路,对教师模型输出进行自动或人工评估,只保留正确和可读性良好的高质量样本。在这一环节会涵盖数学、编程等可客观判定正确性的任务,也会吸收一部分更开放场景下的推理示例,以丰富小模型的训练分布。
为了让更高效的小模型具备像 DeepSeek-R1 一样的推理能力,我们直接使用 DeepSeek-R1 整理的 80 万样本对开源模型进行微调,例如 Qwen(Qwen, 2024b)和 Llama(AI@Meta, 2024)。
NOTE我不知道这里“整理的80万样本”是R1出锅之前的那个原始训练集,还是出锅之后又烘培了80万份样本。
在数据筛选完之后,针对如 Qwen 系列(1.5B、7B、14B、32B、70B)或 Llama 系列(8B、70B)这类开放大模型,直接用上一步得到的“教师数据”进行有监督微调。在训练中,小模型逐步“模仿”教师模型的解题思路与回答格式,从而学会更长、更完整的推理链条与高准确度的解题策略。
2.蒸出的小模型性能评估
从实验结果看,蒸馏后的小模型可在多项推理基准测试(如 AIME 数学竞赛题、MATH-500、编程题等)上取得接近甚至超越较大原模型的表现。例如:
- DeepSeek-R1-Distill-Qwen-7B 在 AIME 上能达到 55.5% 的 Pass@1 准确率,相比未蒸馏版本有大幅提升。
- DeepSeek-R1-Distill-Qwen-32B 更是能取得 72.6% 的 AIME Pass@1,并在 LiveCodeBench 等编码任务上成绩领先其他同等规模模型。
这些结果表明,通过蒸馏自具有强大推理能力的教师模型,较小参数规模的模型依旧可以在推理任务中取得令人印象深刻的水平,且大大减少了推理时的计算与内存消耗。
3.蒸馏 VS. 直接强化学习
有趣的是,若尝试对小模型直接进行大规模强化学习(即不依赖教师模型),往往需要投入庞大的算力,而且最终推理性能也未必能匹敌蒸馏的效果。
- 例如对 Qwen-32B 模型进行大规模 RL,只能达到与QwQ-32B-Preview相近的水准。
- 然⽽,从 DeepSeek-R1 蒸馏⽽来的 DeepSeek-R1-Distill-Qwen-32B 在所有基准测试中表现显著优于 DeepSeek-R1-Zero-Qwen-32B。
通过在多任务、多类型推理数据上的蒸馏,小模型获得了可观的推理能力,又保留了推理速度快、资源占用低等优势。未来如果将蒸馏方法与更多样化的强化学习场景、对齐技术相结合,还可能进一步释放小模型的潜能。对应用场景而言,这意味着在更轻量、可部署性更好的前提下,依旧能获得远超传统小模型的推理效果,真正做到“让小模型拥有大智慧”。
因此,我们可以得出两个结论:
首先,将更强大的模型蒸馏到较小的模型中会产生优异的结果。然而,依赖于本文中提到的大规模强化学习的小模型,往往需要巨大的计算能力,甚至可能无法达到蒸馏所期望的性能。
其次,尽管蒸馏策略既经济又有效,但要超越智能边界,可能仍然需要更强大的基础模型和更大规模的强化学习。
未来展望
以下是DS团队在论文末尾写的内容。
未来,我们计划在以下方向为 DeepSeek-R1 进行投资研究:
- 通用能力:目前,DeepSeek-R1 在函数调用、多轮对话、复杂角色扮演和 JSON 输出等任务上的能力不如 DeepSeek-V3。未来,我们将探索如何利用长链思维(CoT)来提升这些领域的任务表现。
- 语言混合:DeepSeek-R1 目前针对中文和英文进行了优化,这可能导致在处理其他语言的查询时出现语言混合问题。例如,即使查询使用的是非中文或英文的语言,DeepSeek-R1 仍可能使用英文进行推理和回答。我们计划在未来的更新中解决这一限制。
- 提示工程:在评估 DeepSeek-R1 时,我们观察到它对提示非常敏感。少样本提示(Few-shot prompting)会持续降低其性能。因此,我们建议用户直接描述问题,并在零样本设置(zero-shot setting)中指定输出格式,以获得最佳结果。
- 软件工程任务:由于评估时间较长,影响了强化学习过程的效率,大规模强化学习在软件工程任务中尚未得到广泛应用。因此,DeepSeek-R1 在软件工程基准测试上并未显示出相较于 DeepSeek-V3 的巨大改进。未来版本将通过实施软件工程数据的拒绝采样或在强化学习过程中引入异步评估来提高效率,以解决这一问题。
参见
[1] 小冬瓜AIGC:【解读】DeepSeek-R1:RL前真的不需要SFT了吗???
[2] Liu A, Feng B, Xue B, et al. Deepseek-v3 technical report[J]. arXiv preprint arXiv:2412.19437, 2024.
[3] Guo D, Yang D, Zhang H, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning[J]. arXiv preprint arXiv:2501.12948, 2025.