“本文内容基于公开信息与个人推理,仅供参考,非 DeepSeek 官方声明。”
之所以动笔写这篇文章,源于一起 AI 圈经典的“出口转内销”闹剧。
今年 4 月底,不知哪家海外媒体扒拉到国内炒股社区的一篇DeepSeek写的、预测DeepSeek r2更新的、内容离谱水平已经突破当前人类科技上限的ai文,结果不仅当了真,还当成“第一手爆料”大肆宣发。更讽刺的是,这条明显未经核实的内容很快又被国内 AI 媒体当作“外媒报道”原路带回,实现了完美的信源闭环。
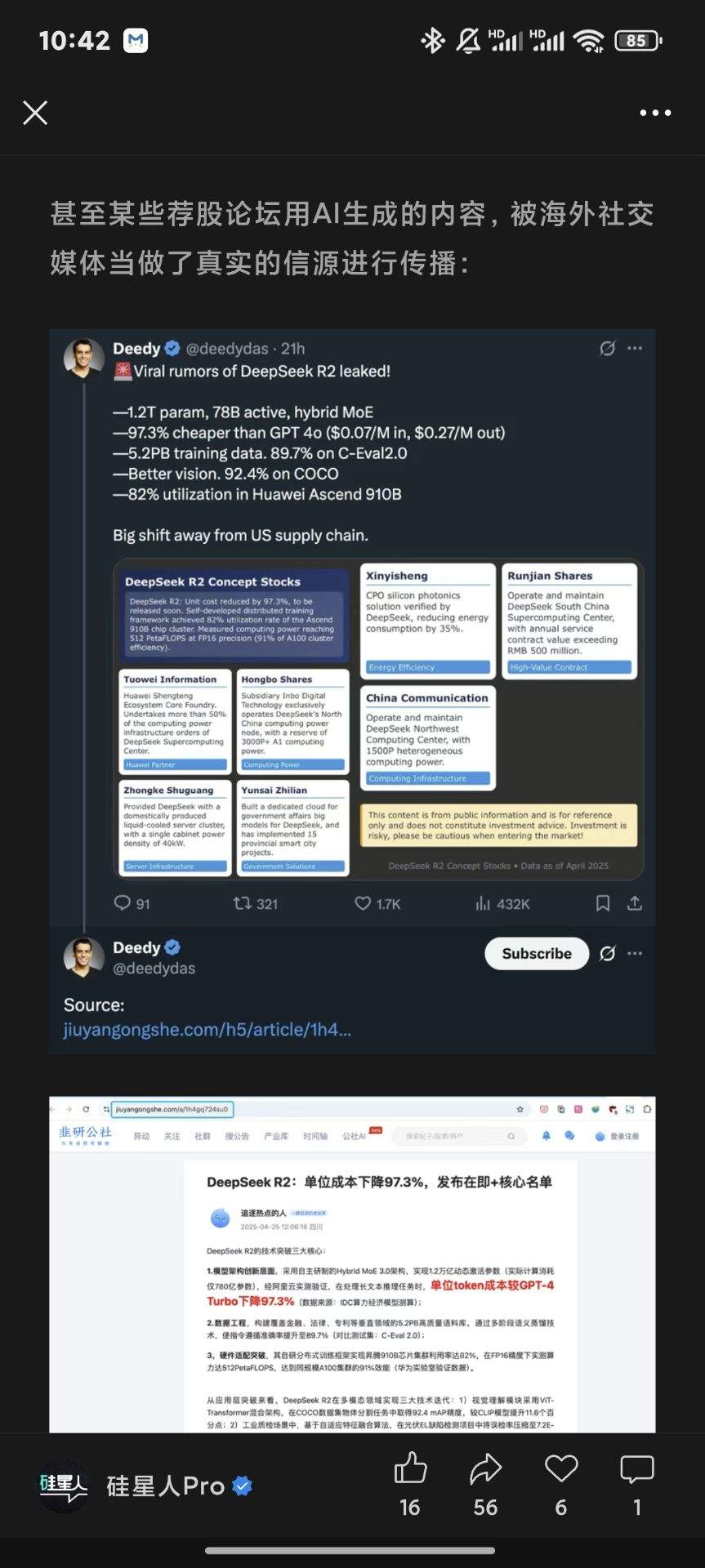
6月2日,《南风窗》居然把这玩意当作“各方透露”的可靠信息,堂而皇之写进自己文章里——令人忍俊不禁。
6月5日最新消息:摩根士丹利也干了!


What can i say?
人类就是这么草台班子,假新闻转一圈大家相互转载相互印证就可以变成多方交叉核验的可靠信源。
时无英雄,使竖子成名。
现在我也来“预测”一次,尝试结合当前业内研发节奏与 DeepSeek 既有的发布规律,对其 2025 下半年模型进展做一份不严肃但尽量靠谱的前瞻。
一、火鸡科学家:DeepSeek 模型的研发&发布节奏
深度求索不愧为幻方旗下的究极理工科公司,在整个大模型行业里,他们可能是最讲节奏感的一家。大家可能已经感受到他们发新模型的频率非常稳定:差不多每两个月就得整点动静。而且不是光有动静,更新还真的有条不紊:两轮小版本热身,接着一个大版本换代,这个“2小1大”规律,从 2024 年年初一路沿用到现在。
以下我们按时间线盘一下 DeepSeek 模型的主要发布节奏:
-
2023.11.16:DeepSeek-LLM V1(7B / 67B)
正式“出道”。全开源+MIT 许可证,一开始就对标 LLaMA,明确了开源路线的技术与社区策略。 -
2024.05.06 / 05.16:DeepSeek-V2 & V2-Lite
上线 236B MoE 架构大模型,激活参数压至 21B,性能更强、推理更快。10 天后补发轻量版 V2-Lite,适配边缘端、小场景。 -
2024.06.14 / 07.24:DeepSeek-Coder V2 系列 编码专项模型上线,128k 上下文+强编程理解,属于 DeepSeek 在 code 模型这条支线上的第一次发力。
-
2024.09.05:DeepSeek-V2.5
版本整合更新,把 V2-Chat 和 Coder-V2 融成一个通用模型。 -
2024.11.20:DeepSeek-R1-Lite
作为R1的前瞻性小模型,进行先期技术测试。 -
2024.12.10:DeepSeek-V2.5-1210
“V2 最后一跳”,增强对话与网页检索模块,为 V2 系列收尾。 -
2024.12.26:DeepSeek-V3(671B MoE)
正式跨代,37B 激活参数、推理速度翻倍、API 接口大改,称得上一次“架构级跨越”。 -
2025.01.20:DeepSeek-R1(685B MoE Reasoner)
推理专项模型上线,对标 OpenAI O1,数理、思维链、工具调用明显强化,甚至还开源权重&训练代码,直接刷爆 HuggingFace。 -
2025.03.25:DeepSeek-V3-0324(小版本更新)
聚焦工具链整合与写作能力,前端能力明显增强。 -
2025.05.28:DeepSeek-R1-0528(小版本更新)
提升对话稳定性、结构化输出(如 JSON / Function 调用)与文学输出质量,幻觉率进一步降低。
从 V2 开始,DeepSeek 基本维持“两个月一大更”的节奏,每个主版本之间都穿插两轮小版本热身或专项模型补强(如 V2 Chat 的 0517 / 0628,Coder 的 0614 / 0724),2024 年 9 月正式实现 Chat / Code 路线融合,最终以 V2.5-1210 封顶,随后迅速过渡到 V3 与 R1 世代,迄今节奏仍旧如一。
所以,我们可以先扮演一下火鸡科学家,纯从发布节奏角度推测一下 DeepSeek 后续的进展:
首先,如果沿用“两个月一次大更 + 中间热身小版本”的节奏推理,那 2025 年 7 月,很可能会迎来 V3.5 的发布。
而 V3.5 相比 V3,大概率将成为一次“结构优化 + 能力扩展”的过渡版本,最有可能引入的,是多模态能力:比如图文对话、网页截图理解,甚至代码可视化与图形化推理等特化能力——这正是目前所有主流模型发力的方向,如o3和Gemini 2.5 Pro故事,DeepSeek 若要维持竞争态势,必须在这条线上补全短板。
接着,大概在 9 月份左右,应该会出现 DeepSeek 两条路线的同步升级——
即:
-
V4:作为通用模型主线的全面迭代,参数规模可能不再暴涨,而是强调推理性能、效率与 Agent 化能力的提升;
-
R2:作为 Reasoner 专线的强化升级,对标 OpenAI的o3后续迭代模型和 Gemini 2.5 Pro 0605&正式版&未来的Gemini 3,进一步提升数理 + 工具链 + 多步推理表现。
如果这个推演成立,那么我们有理由期待:
-
2025.07:V3.5 多模态增强版
-
2025.09/10:V4 通用模型 + R2 推理模型 双线发布
二、目前大模型科研的方向浅析
如果说 DeepSeek 自身的发布节奏是其未来计划的“内因”,那么整个行业的技术发展趋势,则是不可忽视的“外因”。当前大模型领域的科研方向,已经非常清晰地聚焦在如何让模型“更好用”、“更能干活”上。
1. 以 o3 为代表的 Agentic 模型发力:大模型走向实用的必由之路
“Agentic” 这个词,近一年来在 AI 圈的热度持续走高。简单来说,Agentic AI 指的是那些不仅仅能理解和生成内容,更能自主规划、执行复杂任务、并与环境动态交互的 AI 系统。它们具备一定程度的自我导向和决策能力,能够为了达成特定目标而主动调用工具、访问数据库、甚至与其他 AI 或人类协作。Agentic AI 之所以成为兵家必争之地,根本原因在于它是大模型真正落地到产业化、工程化应用的必经之路。
OpenAI在2025年4月正式发布o3模型,被认为是 Agentic AI 的一个重要里程碑。o3 的核心特点在于其强大的 “工具使用”能力和“链式思考”能力。在执行任务时,o3可以主动分析任务需求,自主决定调用哪些工具(例如网络搜索、代码执行、图像生成等),并通过多步骤的推理来完成复杂任务。
OpenAI 甚至提到,o3 可以在一次运行中执行超过 600 次工具调用来解决特别具有挑战性的任务。这种能力使得 o3 在处理需要多方面分析、答案并非显而易见的复杂查询时表现尤为出色。
在国内,阿里巴巴的Qwen 3系列模型在其发布时就明确强调了其先进的 Agent 能力。Qwen3 能够精确地与外部工具进行交互,无论是在其“思考模式”(用于复杂逻辑推理、数学和编码)还是“非思考模式”(用于高效的通用对话)下,都能在复杂的 Agent 驱动任务中达到开源模型的领先水平。
2. 以 Gemini 2.5 Pro 为代表的多模态推理模型:更接近人类的交互与理解
如果说 Agentic AI 解决了模型“如何做事”的问题,那么多模态推理模型则着重于模型“如何理解世界”以及“如何与我们交互”的问题。
Google 在 2025 年初发布的 Gemini 2.5 Pro,在多模态能力上展现了令人印象深刻的进展。它不仅仅能处理文本,还能原生理解和处理图像、音频、视频等多种信息模态。这意味着你可以直接向 Gemini 2.5 Pro 输入视频,并获得结构化的输出,而无需手动进行中间步骤或切换模型——这种跨模态的统一理解能力,使得 AI 更接近人类感知和交互的方式。
目前Gemini 2.5 Pro也是社区公认的真全能模型,堪称高性价比六边形战士
三、跳大神时间到!
如果说前面两部分还算有板有眼、数据充分,那么接下来我们要进入的环节,就纯属信口开河 + 玄学推演 + 大胆假设,小心求证了。
这部分就纯属是我参考 DeepSeek 过去的发布节奏、公开发言中的蛛丝马迹、行业竞品的演进趋势,再加上点人类写手的直觉 + 八卦 + 社区情绪嗅觉,试图“未卜先知”一下 2025 年底之前 DeepSeek 可能还会整出哪些幺蛾子。
以下内容不保证正确,只保证离谱中带点合理,也欢迎大家看完之后自行打脸,或者半年后回来复读——就当是 AI 圈的星象占卜了。
1.DeepSeek V3.5 的目标可能会实现多模态 & 全模态推理
多模态很棒,因此值得一次中版本升级;
单纯的多模态更新又似乎不值得以 AGI 为目标的 DeepSeek 单开一个大版本号——所以我悍跳:
V3.5 很可能将作为一次“通向全模态理解”的关键跳板。在这个阶段,DeepSeek 有望首次引入原生的图像处理能力,支持图片输入、图文对话、表格识别等功能,逐步补齐与 GPT-4o、Gemini 2.5 Pro 等竞品在交互模态上的差距。
除此之外,v3.5可能还会跟Qwen3那样支持自动&手动选择是否开启思考推理模式,支持调整推理预算。
2. Agentic 能力增强:思维链内的模型调用,迈向“执行力强”的AI助手
在 V3.5 或后续版本中,我猜测 DeepSeek 有可能开始显性增强 Agentic 能力,其关键点就在于——支持思维链(CoT, Tree-of-Thoughts)内部的动态模型调用与工具调度,提升整体任务完成速度与执行表现。
换句话说,未来的 DeepSeek 模型很可能会不仅“自己思考”,而且“知道该什么时候调用谁来帮忙”。
这种演进趋势在 o3 身上已经有了清晰体现:通过嵌套式的推理结构,模型可以在思考过程中动态决策是否中断当前流程、调用外部工具(如代码执行器、搜索引擎、函数库),再将结果引入当前上下文继续推理。
3.超长上下文探索
如果说多模态和 Agentic 能力是模型“能力广度”和“执行深度”的拓展,那么超长上下文技术则是支撑这一切的底层基础设施,更是未来构建更复杂、更智能 AI 系统的基石。 我在博客《浅谈ChatGPT的记忆实现机制 兼论工程端记忆设计》就已经解释过模型记忆机制和上下文管理的重要性,因此就不在这里赘述。
我们已经看到,无论是 Google 的 Gemini 2.5 Pro 还是 OpenAI 的 GPT-4.1,都在不遗余力地扩展模型的上下文窗口。Gemini 2.5 Pro 已经支持高达 100 万 token 的上下文窗口,并计划很快扩展到 200 万;GPT-4.1 同样将上下文窗口提升到了 100 万 token。
开源社区做了很大有益探索的还有我们的 Minimax-01 模型
只有拥有了处理海量信息的能力,DeepSeek 的模型才能在更复杂的任务中游刃有余,真正成为能够理解世界、解决问题的智能体。当然,超长上下文也带来了新的技术挑战,例如如何保持模型在长序列中的注意力、如何有效降低计算成本和推理延迟等。但正如 DeepSeek 在其 R1 模型中展现出的创新能力(如通过强化学习激励推理能力),我们有理由相信,这家以技术见长的公司,有能力在超长上下文这个关键领域再次带来惊喜。
4. 进一步“降本增效”:昇腾集群上的训练调优 + 小型 MoE 模型补位
DeepSeek 作为目前最坚定拥抱昇腾集群的头部模型厂商之一,早在 R1 阶段就已经开始将核心模型推理管线部署到昇腾系统之上,形成异构算力环境下的高效推理流程。接下来,降本增效势必会成为其下一阶段优化重心之一。
从目前趋势来看,昇腾的最大价值并不在于性能赶上黄卡,而是在于“足够好 + 足够便宜 + 足够多”。尤其在推理场景中,在美帝封锁已经到穷凶极恶,模型性能已趋稳定的前提下,华卡提供的算力完全可以胜任绝大多数商业级调用需求。
换句话说,昇腾最大的意义在于让“客户侧推理”不再消耗珍贵的 NVIDIA 训练卡资源。
过去,大模型厂商在应对海量推理请求时,往往不得不动用与训练共用的 GPU 集群,造成高昂的资源占用与调度冲突。而现在,通过将推理管线外包到昇腾集群,大模型公司得以 “集中力量办大事”:将 A100 / H100 等昂贵资源彻底回归训练主线,全面加速基础模型的进化节奏。
在这种趋势下,我们有理由相信 DeepSeek 会:
-
进一步压榨昇腾集群在推理侧的性价比极限,从编译器、调度器、模型剪枝、INT4/FP8 量化等层面优化调用效率;
-
搭配推出小型 MoE 模型,为移动端、私有部署、插件系统等高频但轻量的场景提供超快响应能力,建立模型产品线的高低配分层。
5.更长、更稳定且多线程的编程 Agent 框架研发(但大概率不会由 DeepSeek 亲自主导)
其实这一块有点凑数的味了,毕竟从 DeepSeek 一贯的风格来看,他们并没有太大意愿去做复杂系统的工程封装,也鲜少在社区或发布会(如果官网发个通告也算的话)上强调 Agent 框架、插件生态、IDE 插件集成这些开发体验相关的内容。
但这不代表 DeepSeek 会在这一赛道上彻底缺席。随着业界逐步从“能写代码”向“能写能改能跑”的多线程 AI 编程助手过渡,模型本身的结构和能力边界也需要配套升级。就目前趋势来看,DeepSeek 至少会在以下几个维度提供潜在支撑:
-
延长上下文窗口,以支撑大型代码库的理解与调用路径分析;
-
优化思维链结构,提升对复杂编程任务的“多步操作规划”能力;
-
降低推理开销,使得 Agent 可以在多线程并发场景下稳定运行;
-
增强结构化输出能力,便于与执行环境、编译器、终端接口进行更顺畅的通信。
DeepSeek 可能不会亲自去造 IDE,但它会造出可以被 IDE 驱动的强模型;不会去做完整的 Agent 运行框架,但它会在底层提供更适合被封装成 Agent 的模型。在 Jules、Codex、Windsurf、Cursor 等产品把“AI 工程助手”这条路铺通之后,DeepSeek 未来如果希望其模型参与企业级应用,迟早也得提供一条通向“能用”的高速通道。
四、最后再骂一嘴炒股社区
炒股社区是我这辈子见过中老登最多、最傲慢、讨论质量最低的社区之一。你很难在别的地方看到这么多既缺乏基本事实判断能力、又习惯用“我看你这样就不懂”开口的中年人类,在大模型、芯片、算力、AI训练架构等完全不属于他们认知舒适区的领域里,侃侃而谈、信口开河,散播着一堆似是而非、但因为语气自信而极具误导性的观点。
最讽刺的是,他们很多人其实根本不懂自己在说什么,但依旧能把谣言传成“共识”,还能顺带编出几条股价逻辑链自圆其说。
你永远不知道一条“DeepSeek全面采用昇腾集群进行训练”、“xxx传要在美国要上市”的假新闻,会从哪个贴子冒出来,又会在多短时间内被转到什么公众号里变成“知情人士透露”。而当你追溯源头时,却发现整个链条的起点,是一篇用大模型写的预测贴。
当然,他们也不会觉得有什么问题。对炒股社区而言,一切信息都只服务于一个目标:讲一个能让人抬轿的故事。至于那个故事本身是真是伪、有没有技术依据、有没有人真在干活,谁在乎呢?
也正因如此,我觉得写这篇文章是有点意义的。在一个真假信息混杂、专家话语失效、热钱和短线情绪主导讨论的时代,哪怕只是稍微把节奏理清楚、逻辑讲明白,也不失为一种小小的抵抗。