一、学习何以可能?
我们可以从数学中的一个最基本的概念开始:函数。
函数可以被视为一种映射关系,我们给它一个输入,它还我们一个输出,,仅此而已。
因此,气温可以是时间的函数,房价可以是地段的函数,你今天的心情可以是昨晚睡眠质量的函数,女朋友明天的脾气可以是你送的包包价格的函数。世界上几乎所有「A 决定 B」「A 影响 B」的关系&现象,都可以被近似抽象成函数。
我们还可以更复杂一点。上面的例子都是单变量的,即一个输入对应一个输出。但现实世界显然不止这么简单。
比如一个国家一年能生产多少东西,取决于什么?取决于它有多少工人、有多少台机器、技术水平怎么样……经济学家把这些关系压缩成了一个经典的函数——柯布-道格拉斯生产函数(Cobb-Douglas Production Function):
其中 是资本(机器、厂房), 是劳动力(人), 是技术水平, 决定了资本和劳动各自的权重。一整个国家的经济产出,最终也不过被压缩成了一个函数。
再比如,一件商品的价格是怎么决定的?经济学导论课会告诉你「供需决定价格」,但实际进行建模可能是:
其中是价格,供给量是 、需求量是 、消费者预期是 、替代品价格是 ……以及一大堆你可能根本没想到的变量的函数。一杯奶茶卖 18 块钱,背后牵扯着原材料成本、门店租金、竞争对手的定价策略、这条街的人流量、甚至昨天某个网红有没有在小红书上推荐它。
注意,这里和柯布-道格拉斯生产函数有一个本质的不同:柯布-道格拉斯给出了一个漂亮的解析表达式,,形式是已知的,你只需要用数据去拟合几个参数就行。但供需定价呢?我们可以在直觉层面上进行确信,相信这些变量和价格之间存在某种函数关系,但这个真实的、具体的、物理的、实际的 长什么样,没有人能写出来。
这其实才是现实世界的常态。我们能感受到输入和输出之间存在规律,但这个规律的解析形式是未知的。
所以从某种意义上说,「建模」这件事的本质,就是在声称一个信念:我相信这里存在一个函数。 物理学家相信粒子的轨迹是初始条件的函数,经济学家相信产出是资本和劳动的函数,医生相信你的血压是饮食、运动、基因的函数。整个科学大厦都建立在这个信念之上——世界不是随机的,输入和输出之间存在某种确定的、可描述的关系。
当然现代科学也并不否认随机性,而是认为随机性和结构性可以同时存在,这是统计学习的内容了,此处按住不表
但仅仅相信「函数存在」还远远不够。
一个纯粹任意的函数是不可学习的。我们可以想象一个函数,对每一个输入都给出一个完全随机的输出,这样的函数即使存在,你也拿它毫无办法:你观测了一万个点,对第一万零一个点的预测仍然是瞎猜。因为你在已知点上获得的一切知识,对未知点没有任何约束力。
所以科学(以及一切归纳推理)其实偷偷押注了第二个更强的信念:这个函数不仅存在,而且是平滑的。
所谓平滑,直觉上很好理解:你稍微动一下输入,输出也只是稍微动一下。水温从25°C 升到26°C,密度只会变化一点点;你往东走一公里,海拔不会突变三千米(在绝大多数情况下)。输入和输出之间有某种「渐进的、可预期的」关联,没有突然的跳崖和瞬移。
数学上对这个直觉最干净的刻画之一叫 Lipschitz条件(利普希茨条件),如果存在常数 ,使得对任意输入 :
就称 是 Lipschitz 连续的。这个不等式说的事情很朴素:输出的变化幅度,永远不会超过输入变化幅度的某个固定倍数,变化率有其天花板。
平滑性也因此给了我们一样至关重要的东西:局部可推断性。如果你知道了 的值,那么 附近的点, 的值也不会离 太远。每一个已知的观测点都不是孤立的,它的信息可以「辐射」到周围的邻域,为你还没观测到的地方提供约束;而在这个约束之下,我们可以合理预期这些没观测到的地方的值。
这就是归纳法的数学底气:过去的经验之所以能指导未来,是因为「未来」就住在「过去」的邻域里,而平滑性保证了邻域内的行为是可预期的。
如果故事到这里就结束了,那就太好了,可惜并没有。
问题出在维度上。
我们前面举的例子,如温度与密度,位置与海拔,输入都是一两个变量,在此基础上我们采十几几十个点就能把函数轮廓描绘个大概。但回忆一下那个奶茶定价的例子:我们的输入变量可能是几十个、上百个变量,而在机器学习真正面对的场景里,维度还要再夸张几个数量级——一张普通的照片有几十万个像素,每个像素都是一个维度;一段文本经过分词后也是一个高维的离散空间。
我们姑且可以把一张灰度图想象成一个巨大的数字表格,每个格子通常里会填一个介于0到255之间的整数,表示在这个位置的亮度,那么一张 200 * 200的灰度图就是200行、200列,总共40000个格子,也就四万维;即 的灰度图 = 40000 个格子 = 40000 个数字 = 40000 维空间里的一个点。
而彩色图就更复杂了,彩色图每个像素不再只是一个数字,而是三个——R(红)、G(绿)、B(蓝)各一个值。所以同样 的彩色图就需要 个数字,即 120000 维空间里的一个点。现代手机里的一张普通的照片(1000 * 1000)可能就有三百万维。
哦有同学看到这里就想问了,为什么要把一张图片当成几十上百成千万维的东西?
毕竟我们看一张人脸照片,我们感受的是「这是一张人脸,嚯可能还怪好看」,而不是「这是一个四万维空间中的坐标点,哇数学真是巧夺天工」。我们觉得这张脸好看或不好看,用的是直觉,不是在心里默算几万个像素值的函数。那为什么机器非得活在这么高的维度里?

比如这张酒寄彩叶和辉夜的截图,你第一反应大概也许是哇好可爱,而不是下面这一坨👇

因为机器没有直觉。
我们能一眼认出这是一张人脸,是因为我们的祖先足够会恣意生长,我们的大脑在几十万年的演化和几十几二十几几十几年的生活经验里,已经帮我们把「像素→语义」这条路修好了。我们看到的不再是像素或者别的什么抽象东西,我们看到的是眼睛、鼻子、表情、情绪,我们的大脑已经替我们完成了降维。但机器拿到的输入就是原原本本的、赤裸裸的像素值。对于一个从零开始的算法来说,它接收到的就是一串数字,这串数字有多长,它的世界就有多少个维度。
这不只是图片的问题。我们给计算机&模型一段文本,经过分词之后就是一个高维的离散序列;给它一段语音,就是一串长采样点;给它一个用户的行为记录,就是一个由几百个特征拼成的向量。在机器学习的语境里,维度不是我们选择的,而是原始数据「天生自带」的。我们没有办法假装一张图片只有三个变量,因为少了任何一个像素,信息就不完整了。
所以困境就在于此:一方面,我们好不容易论证了平滑性让学习成为可能——只要你在输入空间里积累足够密的观测点,就能靠「领域推断」来覆盖未知区域。另一方面,输入空间的维度是被数据的原始表示硬生生撑起来的,而在这样的高维空间里意味着 「邻域」变成了一个极其奢侈的概念。
在一维空间里,我们想把一条线段均匀覆盖到每隔 0.01 就有一个样本点,只需要 100 个点。在二维空间里,同样的密度需要 个点。三维空间? 个点。推广到 维,我们需要 个点,即样本量随维度指数增长。
这就是所谓的维度灾难(Curse of Dimensionality)。
我们刚刚费了好大力气建立起来的推理链条「平滑性保证了邻域内可推断」在高维空间里突然变得苍白无力。不是因为平滑性失效了,而是因为我们根本凑不齐一个所谓的邻域。我们的训练样本再多,放进一个几十万维的空间里也不过是汪洋大海中稀疏得可以忽略不计的几粒沙。每一个数据点都是一座孤岛,「辐射」的信息在它到达最近的邻居之前就已经衰减殆尽了。
所以,光有「函数存在」和「函数平滑」这两个信念是不够的。如果高维空间真的是一片均匀的荒原,那么无论我们的模型多精巧,我们的数据多海量,学习都是无望的。
我们需要第三个信念。
而幸运的是,现实世界中的很多有意义数据往往表现出某种结构,来满足这个信念——高维数据的真实有效维度,远比它的表面维度低得多。
一张 的彩色照片有三百多万个像素维度,但并不是每一种像素排列都对应一张「有意义的」图片。随机生成三百万个像素值,你几乎必然只会得到一团噪声。所有「看起来像人脸」的照片,只占据了这个天文数字维度空间中极其微小的一部分,而它们挤在一条弯弯曲曲的低维曲面上。
这就是流形假设(Manifold Hypothesis):高维数据实际上近似分布在一个低维的光滑流形上。所谓流形,你可以想象一张被揉皱后塞进三维空间的纸,它在三维空间里弯弯曲曲、褶皱重叠,但它自身只有两个维度。你站在纸面上行走,永远只需要「前后」和「左右」两个方向就够了,你感受不到第三个维度的存在。
同理,人脸照片虽然活在百万维的像素空间里,但所有合理的人脸构成的集合可能只是一个几百维甚至更低维的曲面。沿着这个曲面走,人脸会连续地变化,如眉毛渐渐挑起,嘴角慢慢扬起,光影从左侧柔和地转移到右侧,而大概率不会突然从一张脸跳成一团马赛克。
当然流形假设也只是一种假设,它更像是帮助我们理解高维数据为何仍可学习的一种强而有力的近似视角
现在把这三层信念叠在一起看:
- 世界存在规律——输入和输出之间有函数关系
- 规律是平滑的——变化是有界的,小扰动只带来小偏移
- 数据的有效维度是低的——我们不需要覆盖整个高维空间,只需要覆盖那个低维流形,而数据是有结构的,相邻的点共享相似的语义
前两条给了我们「局部能推断」,第三条把「局部」从不可企及变回了可操作。三条合在一起就是一句话:在这个宇宙里,相似的原因倾向于产生相似的结果。基于此,有限的样本才能真正拼出未知函数的轮廓,归纳法才真正站得住脚,机器学习才从数学上变得可行。
二、把语义变成几何
好的,长舒一口气,现在我们知道了:数据虽然表面上住在一个几十万维的空间里,但实际上挤在一个低维的光滑流形上。这是个好消息。但紧接着就有一个非常实际的问题:
这个流形在哪?长什么样?我们怎么在上面做计算?
困难在于,流形是弯曲的。它蜷缩、折叠、扭结在高维空间里,像一团被揉皱的纸塞进了一个巨大的房间。两个数据点在原始的高维空间里可能离得很近,但沿着流形走其实隔着十万八千里——就像一座山两侧的住户,直线距离穿过山体可能只有 500 米,但沿着山路走要绕上 20 公里。反过来也成立:沿着流形明明紧挨着的两个点,被折叠之后可能散落在高维空间的天涯两端。
换句话说,原始高维空间里的距离,并不能真实地反映数据之间的语义关系。你在像素空间里计算同一个人脸但是亮度不同的两张照片的欧氏距离,得到的数字几乎是没有意义的;把所有像素整体调亮 10%,像素距离变了一大截,但这显然还是「同一张脸」。
所以我们真正需要的是:找到一种映射,把数据从弯曲的高维流形「展开」到一个相对低维的、平坦的向量空间里,并且让这个空间里的距离较为忠实地反映数据在流形上的真实关系。
近的东西映过去还是近的,远的东西映过去还是远的。语义上相似的数据点,在新空间里挨在一起;语义上无关的,彼此远离。
这件事,就叫 Embedding——把原始对象映射为向量,使得与任务相关的相似性、结构或关系,能在向量空间里被几何地度量和操作。
目标说清楚了。但目标从来不是最难的部分,怎么做到才是。
要把「语义相近的东西映射到几何上相近的位置」,你首先得回答一个问题:你怎么知道什么和什么是语义相近的?
我们之所以需要 Embedding,恰恰是因为原始数据层面的距离不能反映语义,如像素空间里的欧氏距离对「这是不是同一张脸」几乎没有发言权。而现在你要学一个映射,让语义相近的东西在新空间里距离近?那你得先有一把语义的尺子。可如果我们已经有了这把尺子,还学 Embedding 干嘛?
这看上去像是一个循环论证,而人类中最聪明的那部分大脑给出的解法是:我们从来不直接定义「语义相近」,我们定义的是一个更弱、更容易获取的东西——共现。
1.你的邻居定义了你
让我们从语言开始,因为语言领域的 embedding 故事最经典,也最符合直觉。
20世纪中叶,语言学家 J.R. Firth 说过一句被引用到烂的话:
“You shall know a word by the company it keeps.”
一个词的意义,由它的同伴决定。
这句话的意思是:你不需要去查词典定义来理解「咖啡」是什么意思。你只需要观察「咖啡」经常和哪些词一起出现——「喝」「杯」「苦」「提神」「早晨」「拿铁」——这些共现的伙伴,就已经圈定了「咖啡」的语义轮廓。
反过来想,如果一个外星人从未接触过地球文明,你递给它一本五百万字的中文小说,它完全不认识任何一个字。但如果它足够聪明,它会发现:「猫」和「喵」总是出现在相似的上下文里,「狗」和「汪」也是,而「猫」和「抵押贷款」几乎从不出现在同一段话里。仅凭共现的统计规律,不需要任何先验知识,它就能开始构建出一张模糊的语义地图,划清哪些词彼此相关,哪些词毫无关系。
这个直觉,就是几乎所有词向量方法的哲学起点。
在2013年,Google 的 Tomas Mikolov 等人提出了 Word2Vec,正式把这个直觉变成了一个可计算的算法。Word2Vec 的核心思想可以浓缩成一句话:
让一个浅层神经网络去做一个「完形填空」的任务,然后偷走它的中间产物。
具体来说,Word2Vec 有两种架构,我们先看更直觉的那个——Skip-gram。
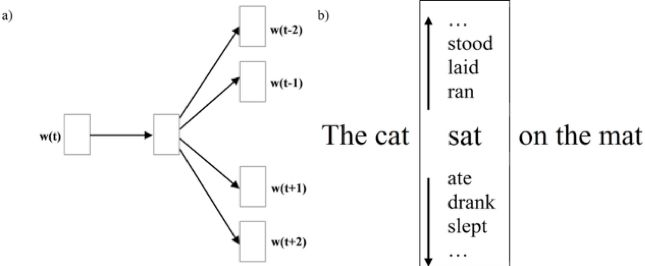
Skip-gram 的任务很简单:给定一个中心词,预测它的上下文词。比如有这么一句话:
“今天天气很好我们去喝咖啡吧”
如果中心词是「喝」,窗口大小为 2,那模型的任务就是:看到「喝」,请预测出「我们」「去」「咖啡」「吧」这几个词。
具体怎么做呢?我们给词表里每一个词分配一个随机初始化的向量(没错,一开始是随机的,完全没有任何语义信息)。然后我们训练一个简单的模型:输入中心词的向量,经过一层运算,输出一个概率分布,表示「词表里每个词出现在这个中心词上下文中的概率」。
训练目标是:让真实出现在上下文里的词概率高,没出现的词概率低。
然后,就是大力出奇迹的时刻:我们拿几十个 GB 的文本语料,几十亿个这样的(中心词, 上下文词)训练对,反复训练。
训练完之后,神奇的事情发生了。
那些一开始完全随机的词向量,在反复被梯度更新之后,自发地排列出了有意义的几何结构。
到底有多有意义?有意义到什么程度?
答案是:有意义到可以做算术。
Mikolov 等人在论文中展示了一个后来被引用了无数遍的例子:
把「国王」的向量减去「男人」的向量,加上「女人」的向量,得到的结果在整个词表的几十万个向量里,最近邻居恰好是「王后」。
第一次看到这个结果的人通常会有两个反应:第一反应是”卧槽好酷”,第二反应是”等等,这为什么能 work?”
让我们想一想这意味着什么。
得到了一个差向量,这个差向量指向的方向是什么?它剥离了”国王”中”男性”的那部分语义,剩下来的大约是”皇室的、统治的、至高的”这些属性。换句话说,这个差向量近似编码了「royalty(皇室身份)」这个抽象概念的方向。然后你把这个方向加到 上,就得到了”一个拥有皇室身份的女性”——Queen。
更让人震惊的是,这不是一个孤例。类似的线性关系在词向量空间里大面积涌现:
(首都关系)
(比较级变换)
(时态变换)
这意味着词向量空间里存在着近似平行的语义方向。“男性→女性”是一个方向,“原级→比较级”是一个方向,“国家→首都”是一个方向。这些方向彼此独立,可以自由叠加组合。向量空间里的线性运算,居然对应了人类语义层面的类比推理。
回到我们第一节讲的那件事——“把语义变成几何”。到这里你可以真切地感受到这句话不是比喻,它是字面意义上的事实:语义关系被编码成了向量空间中的几何关系,概念之间的类比被编码成了平行四边形。
当然,诚实地说,这种线性类比的魔法也有它的边界。它在语法变换(时态、单复数、比较级)和简单的关系类比(国家-首都、性别对调)上表现惊艳,但在更复杂、更抽象的语义关系上就开始吃力了——你大概算不出 这种东西,因为越抽象的概念,其语义关系越不可能被一个固定方向的线性偏移所捕获。
但这不影响这个发现的意义。它第一次向我们展示了一件事:一个纯粹从统计共现中学出来的向量空间,其内部自发形成的几何结构,居然与人类的概念系统存在某种深层的同构。
没有人教它”国王和王后的关系等价于男人和女人的关系”,没有人提供任何关于人类社会结构的先验知识。它只是读了几十亿个词,然后这些关系就从统计规律中浮现了出来。
2.从语言到一切:对比学习与更一般的 Embedding
Word2Vec 的故事很漂亮,但有一个显而易见的局限:它依赖「上下文窗口」这个概念。一个词的左边几个词、右边几个词构成它的上下文,这是语言文本天然具备的结构。
但如果我们想给图片学 Embedding 呢?一张照片没有”上下文窗口”——它的左边不是另一张照片,它的右边也不是。一段蛋白质序列、一个分子结构、一条用户行为轨迹,都没有现成的”上下文”可以用来做预测任务。
所以我们需要后退一步,问一个更根本的问题:Word2Vec 真正的成功秘诀到底是什么?
不是”预测上下文”本身。预测上下文只是一个手段,一个代理任务。它真正做到的事情是:通过一个巧妙设计的目标函数,让语义相似的对象在向量空间里被迫靠近,让语义无关的对象被推远。
如果我们把这个”靠近-推远”的逻辑从语言的上下文中抽象出来,就得到了一个远为通用的学习范式——对比学习(Contrastive Learning)。
对比学习的核心机制可以压缩成三步:
第一步,构造”正样本对”和”负样本对”。 正样本对是我们认为”应该靠近”的两个东西,负样本对是”应该远离”的两个东西。
在 Word2Vec 里,正样本对就是(中心词,真实出现在其上下文中的词),负样本对就是(中心词,从词表里随机抽一个大概率无关的词)。但在别的领域,构造正负样本对的方式可以完全不同:
- 图像:取一张图片,对它做两次不同的随机变换(裁剪、翻转、调色、模糊),得到的两个版本就是正样本对。随机抓另一张图片做负样本。
- 文本:一句话和它的同义改写是正样本对。随机抓一句不相关的话做负样本。
- 多模态:一张图片和描述它的文字是正样本对(CLIP 就是这么干的)。同一张图片和一段完全不相关的文字是负样本对。
第二步,用一个编码器把每个样本映射成向量。
第三步,训练编码器,让正样本对的向量尽可能近、负样本对的向量尽可能远。
就这么简单。整个训练过程不需要任何人工标注的标签,不需要任何领域先验知识,你只需要定义”什么算一对正样本”。
这里有一个非常精妙的地方值得停下来品味一下。
以图像的对比学习为例。我们把同一张猫的照片裁剪一下、翻转一下、色调调暖一点,然后要求模型认为这些变换后的版本”本质上是同一个东西”。这意味着什么?意味着我们在告诉模型:裁剪、翻转、色调变化是”不重要的”表面差异,你应该忽略它们。
那模型为了让这些变换后的版本映射到相近的向量,它就被迫去捕捉那些在所有变换中都保持不变的特征——也就是物体的形状、结构、语义类别这些更深层的东西。
换句话说:你选择对什么变化保持不变性(invariance),就等于在隐式地定义什么是”语义”,什么是”噪声”。 数据增强的策略看似是个工程细节,实际上是一个深刻的认识论选择:你在告诉模型,这个世界的哪些维度是本质的,哪些是偶然的。
这和人类认知的某些侧面惊人地相似。你之所以能在不同光照、不同角度、不同遮挡条件下认出同一个人,正是因为你的视觉系统经过多年训练,学会了对这些”表面变化”保持不变性,只提取那些与”这个人是谁”相关的本质特征。
所以对比学习不只是一种技术方案,它其实在做一件很哲学的事情:它在学习区分本质与偶然、信号与噪声、不变量与变换群。而这件事,本质上就是人类自柏拉图以来一直在追问的那个问题——什么是事物的”本质”(essence),什么是”现象”(appearance)?
3.多面孔的词
Word2Vec 给每个词分配一个固定的向量。“苹果”就是”苹果”,无论它出现在什么句子里,它的向量都是同一个。
但聪明的我们(或者说聪明的先辈们)马上就能意识到这里有个问题:
“我咬了一口苹果,汁水四溅。"
"苹果发布了新款 MacBook Pro。”
这两个”苹果”的含义天差地别,一个是水果,一个是科技公司。但在 Word2Vec 的世界里,它们共享同一个向量。模型不得不把这两种完全不同的语义硬生生地压缩、折叠、平均到同一个点上,最终得到的是一个模糊的、谁都不精确代表的混合体——一个既有点像水果又有点像科技公司的四不像向量。
这不仅仅是”苹果”的问题。自然语言中一词多义的现象无处不在:“打”可以是打人、打电话、打酱油、打车;“花”可以是花朵、花费、花心;“right”可以是正确的、右边的、权利。语言的本质就是多义的、语境依赖的。一个词的意思从来不是由这个词本身单独决定的,而是由它所处的整个句子、段落、甚至对话的上下文共同决定的。
所以静态词向量的瓶颈不是技术上的缺陷,而是一个根本性的建模假设错误:它假设”一个词 = 一个含义 = 一个向量”,但现实世界中的语义根本不是这样运作的。
出路在哪?其实第一节就已经埋下了线索。
回忆一下 Firth 的那句话:“一个词的意义,由它的同伴决定。” Word2Vec 用了这个思想的一半——它在训练阶段利用上下文来学习词向量。但训练完成之后,上下文就被丢掉了,每个词被钉死在一个固定的位置上。
真正彻底贯彻 Firth 哲学的做法应该是:不仅在训练时利用上下文,在使用时也让每个词的表示根据当前的上下文动态生成。
这正是 2018 年前后的一系列工作(ELMo、GPT、BERT)所做的事情。
以 BERT 为例。BERT 不再给每个词一个固定的向量,而是给定一整个句子,让模型在看到完整上下文之后,为句子中的每一个词各自生成一个向量。这意味着”苹果”在”我咬了一口苹果”中的向量,和它在”苹果发布了新款 MacBook”中的向量,是不同的。
同一个词,在不同的语境中,获得不同的表示。这才是 Firth 那句话的完整实现。
这是怎么做到的?核心机制叫 Self-Attention(自注意力)。
直觉上可以这样理解:句子里的每一个词在生成自己的表示之前,会先”看一眼”句子里的所有其他词,然后根据相关程度决定从每个词那里”借”多少信息过来,用来调整自己的表示。
在”我咬了一口苹果”中,“苹果”会重点关注”咬""一口”这些词,从它们那里借来的信息会把”苹果”的表示推向”水果”的语义方向。而在”苹果发布了新款 MacBook”中,“苹果”重点关注的是”发布""MacBook”,这些信息会把它的表示推向”科技公司”的方向。
同一个词的向量不再是固定的坐标点,而是一个随上下文流动的、活的表示。
如果用我们第一节的流形语言来说:Word2Vec 是在流形上给每个词钉了一个固定的图钉,而 BERT 允许每个词在流形上滑动,滑到当前语境所指示的那个位置。
这个从静态到动态的跃迁,不只是技术上的进步,它还回应了语言哲学中一个古老的争论:词语的意义到底是存储在词典里的固定实体,还是在每次使用中被重新协商出来的?
维特根斯坦在《哲学研究》中给出了他的答案:“一个词的意义就是它在语言中的用法。“(The meaning of a word is its use in the language.)意义不是一个被锁在保险柜里的静态对象,等你来查阅;意义是在具体的语言游戏(Sprachspiel)中、在特定的生活形式(Lebensform)中被实时生成的。
从这个角度看,BERT 做的事情恰恰是维特根斯坦语言观的计算实现:词的表示不是预先定义好的,而是在每一次具体的”语言游戏”(每一个具体的句子)中被动态地、语境地生成的。
这是不是就意味着 BERT”理解”了语言?那又是另一个问题了。但至少在表示这个维度上,它比 Word2Vec 更忠实于语言的本质。语言从来就不是一个词一个意思的字典,而是一片语境之间相互映照、彼此定义的动态网络。
三、计算相似性
1.下沉到语义层
在第一节,我们论述了学习之所以可能,依赖于三个关于世界的信念:存在规律、规律平滑、有效维度低。第二节,我们展示了如何通过共现、对比、动态上下文等手段,把原始数据映射到一个向量空间里,让语义关系变成几何关系。
但到目前为止,我们一直在讨论的是 Embedding 是什么以及怎么做到的。现在该正面回答标题里的那个词了:意义。
Embedding 的意义到底是什么?
在 embedding 出现之前,人类当然也已经有了计算“相似性”的方法。TF-IDF、BM25、关键词匹配——这些方案支撑了整整一个时代的搜索引擎,让你在 Google 搜索框里输入几个关键词就能从几十亿网页中找到相关结果。它们工作了很多年,而且工作得还不错。
但它们衡量的是什么?是词汇的重叠。
两段文本共享了多少相同的词?共享的词在各自文本中有多稀有(因此有多重要)?本质上,这些方法在做的事情是数数——数两段话之间有多少个相同的字符串出现了。
这在很多场景下管用,但它有一个致命的盲区:语言可以用完全不同的词说同一件事。
“我想买一台笔记本电脑”和”推荐一款轻薄本”,关键词几乎没有重叠,TF-IDF 算出来的相似度接近于零。但任何一个人类都知道,这两句话说的是同一件事。反过来,“苹果是一种水果”和”苹果是一家公司”共享了大量相同的词,关键词方法会认为它们高度相似,但它们的意思南辕北辙。
关键词方法度量的是表述的相似性,而不是意义的相似性。 它能告诉你两段话长得有多像,却无法告诉你它们说的是不是同一回事。
Embedding 做到的事情,是让”相似性”的计算从词的表面下沉到了语义层。
当两段文本、两张图片、两段代码都被映射成向量之后,它们之间的语义关系就变成了向量空间里的几何关系。“这两个东西意思有多像?“这个关键词方法答不好的问题,现在只需要:
一行余弦相似度。
这不是一件小事,因为一旦”相似性”变成了可计算的,一整类原本只能靠人类智能完成的操作就突然变成了几何运算:
- 语义检索:从十亿条文档里找到和你的问题最相关的那几条——本质上就是在向量空间里做最近邻搜索。
- 聚类:把几百万条用户反馈自动归类成几十个主题——本质上就是在向量空间里找密度峰值。
- 推荐:找到和你喜欢的东西”气质相似”的东西——本质上就是在向量空间里画一个以你的偏好为圆心的球。
- 去重与对齐:判断两个来源不同的条目是否指向同一个实体——本质上就是看两个向量是不是落在了同一个邻域里。
这些任务在表面上看起来千差万别,但在 Embedding 的视角下,它们全部退化成了同一个数学问题:在向量空间里度量距离。
而在大语言模型的时代,这件事还有一个更具体、更关键的应用:RAG(Retrieval-Augmented Generation,检索增强生成)。
LLM 的上下文窗口是有限的。即使是最前沿的模型,能一次性处理的文本长度也有天花板。参数是有限的,世界是无限的,大模型不可能把人类有史以来的所有知识都压缩进参数里。所以当你问 LLM 一个它参数里没有记住的问题时,它要么诚实地说”我不知道”,要么不那么诚实地开始编造。
后者可能会更加常见
RAG 的解决方案是:在 LLM 回答之前,先用 Embedding 模型把你的问题和一个外部知识库里的所有文档都映射成向量,找到最相关的几条,塞进 LLM 的上下文里,然后让它基于检索到的真实信息来生成回答。
在这个架构里,Embedding 模型充当的角色是什么?是给 LLM 装上了一个可检索的外部记忆。LLM 负责思考和表达,Embedding 模型负责在浩如烟海的信息中找到那几颗最相关的针。没有 Embedding,RAG 就不存在;没有 RAG,LLM 就只能困在自己的参数之中,像一个博闻强识但与世隔绝的学者,只能回忆,不能查阅。
2.建立语义世界的坐标系
Embedding 的意义当然不止于”让某些具体任务变得可行”。真正深刻的地方在于:一个好的 Embedding 模型,其价值不在于它自己能完成什么任务,而在于它为所有下游任务提供了一个共享的语义坐标系。
让我们做一个类比。
1637 年,笛卡尔做了一件看起来很简单的事:他在平面上画了两条互相垂直的线,然后宣布,平面上的每一个点都可以用一对数字 来表示。
这件事本身没有解决任何具体的几何问题。它没有告诉你如何求圆的面积,没有帮你证明勾股定理,没有给出任何新的定理或公式。它做的事情更加基础,也更加深远:它给几何世界提供了一种统一的表示语言。
有了坐标系,圆变成了 ,抛物线变成了 ,两条直线的交点变成了解方程组。几何问题不再需要逐个用巧妙的辅助线和灵感来攻克——它们被统一翻译成了代数问题,而代数有一整套系统的、机械的、可编程的求解方法。
Embedding 模型对语义世界做的事情,与笛卡尔对几何世界做的事情,在结构上高度相似:它给语义世界提供了一个坐标系。
有了这个坐标系,一段文字不再是一串不可运算的符号,而是空间中一个有坐标的点。一张图片不再是一团不可比较的像素,而是同一个空间(或经过对齐的相邻空间)里的另一个点。一段代码、一条蛋白质序列、一个用户行为轨迹,都可以被映射成向量,拥有坐标,参与运算。
而当不同模态的数据被映射进同一个向量空间时,事情就变得更加有趣了。OpenAI 的 CLIP 模型把图片和文字映射到了同一个 Embedding 空间里。这意味着你可以用一句话”a cat sitting on a windowsill watching the rain”去检索一张从未被任何人用文字描述过的照片,只要那张照片的视觉语义和这句话的文本语义在向量空间里足够接近。这背后的意义远超”以文搜图”这个具体功能——它意味着图像和语言之间那条古老的模态鸿沟被桥接了,不是通过人工标注,不是通过规则匹配,而是通过把两种截然不同的符号系统投射到同一个几何空间里,让它们的距离变得可度量、可比较、可运算。
但坐标系本身不干活。笛卡尔画完那两条线之后,也没有立刻算出什么新东西。坐标系的价值是基础设施性的:它让一整类操作从”需要专门设计”变成了”平凡”,让后来者可以在它之上直接建造,而不需要每次都从最底层开始。
如果你想做一个”智能”系统,比如一个能理解用户意图的搜索引擎、一个能自动归类工单的客服系统、一个能推荐相似论文的学术平台……在没有通用 Embedding 的年代,你需要做什么?
答案是:每一个任务,都得在”理解数据”这件事上从头来过。做情感分析?从原始文本开始,设计特征工程,训练一个分类器。做文档检索?换一套特征、换一种索引结构、再训练一个模型。做推荐系统?再来一遍。每个系统都在重复同一件事的前半段——理解数据,只有后半段——做决策——才是各自不同的。
而在 Embedding 的体系下,“理解”被抽离成了一个独立的、可复用的环节。一个通用的 Embedding 模型负责把原始数据映射成向量,完成从”符号”到”坐标”的翻译。下游任务只需要在坐标上做轻量操作:检索是最近邻搜索,聚类是找密度峰值,分类是在向量上叠一层线性层,推荐是画一个以用户偏好向量为圆心的球。“理解”变成了公共层,“决策”才是各个任务自己的事。
当 Embedding 模型升级时,所有依赖它的下游任务在逻辑上都能受益;它们的架构不需要重新设计,业务代码不需要重写。这种解耦还带来了一个极其重要的工程性质:“理解”可以离线预计算,而”使用”几乎是免费的。
把一段文本送进 Embedding 模型是有成本的:它需要经过多层神经网络运算,最终产出一个向量。但这件事只需要做一次。向量一旦算好,存下来,之后的每一次检索、比较、聚类,都只是向量之间的数学运算——点积、余弦、L2 距离,而这些运算的开销相比神经网络推理低了好几个数量级。
这意味着什么?意味着你可以把一个知识库的一千万条文档全部 embed 一遍,把向量存进数据库,然后之后每次用户提一个问题,你只需要 embed 这一句话(一次推理),再去数据库里做一次向量搜索(毫秒级),就能找到最相关的几条文档。Embedding 把”理解”从一个实时的、反复的开销,变成了一个一次性的、可摊销的投资。
而这种新的查询模式——“找到和这个意思最接近的东西” 也催生了一类新的基础设施:向量数据库(Vector Database)。
传统数据库回答的问题是精确匹配的:「这条记录在哪?」;我们需要按主键查找、按条件过滤、按字段排序。这些操作的前提是,你得精确地知道自己在找什么:一个确切的 ID、一个明确的关键词、一个具体的数值范围。但在语义检索的场景里,你常常不知道自己在找什么,至少不知道它的精确表述。你知道的只是一个意思:「跟这个意思差不多的东西在哪?」这不是精确匹配问题,这是近似最近邻问题。
向量数据库(Pinecone、Milvus、Qdrant、Weaviate……)就是为这种查询模式而生的。它们用 HNSW、IVF 这类专为高维向量空间设计的近似最近邻算法,在几十毫秒内从几十亿条向量中找到和你的查询向量最接近的那几个。
不过向量能力也正在被传统数据库吸收(PostgreSQL 的 pgvector、Elasticsearch 的 dense vector),而专用向量数据库也在补齐元数据过滤、权限控制等传统能力。更准确的说法是:Embedding 改变了”查找”这个动作的性质,从匹配字符串变成了度量意义的距离,而数据库的能力不得不扩展来适应这种新的查询语义。
回到起点:为什么能 Work?
写到这里突然感觉有点圆不回来了,摊子铺太大了
在最后,我们可以再问一个问题:这一切为什么能 work?
不是在问算法为什么有效,不是在问 Transformer 的注意力机制为什么比 RNN 好,不是在问 HNSW 索引的时间复杂度,这些都是工程层面的”为什么”,都有各自精确的技术解答。我想问的是一个更底层的、几乎带有形而上学色彩的”为什么”:
为什么语义可以被几何化?为什么意义之间的关系能够被向量之间的距离所忠实地刻画?
答案,其实在我们第一节就已经给出了,只是当时它穿着数学的外衣,不太容易被认出来。
让我们把它换一种方式说一遍:这个世界是局部平滑的。
不只是物理世界的那种水温升高一度,密度只变化一点点。语义世界也是。一个句子里替换掉一个词,意思只偏移一点点(大概)。一张人脸照片的光照微微改变,它传达的”这是谁”的信息只扰动一点点。一个概念和它最近的相邻概念之间,总是存在着可以被连续插值的过渡地带,而不是一道突兀的悬崖。
“咖啡”和”拿铁”之间的语义距离很近。“拿铁”和”卡布奇诺”也很近。“卡布奇诺”和”摩卡”也很近。你可以沿着这条路一步步走下去,从咖啡走到茶,从茶走到饮料,从饮料走到食物,每一步都是一个小小的、平滑的语义偏移。这条路不会在某个节点突然跳到”量子力学”或”劳动仲裁”,除非你刻意绕了一条非常古怪的路径。
语义空间和物理空间一样,服从某种局部的利普希茨条件:相邻的输入产生相邻的输出,小扰动只引起小偏移。
而 Embedding 之所以能 work,不是因为某个算法足够聪明,不是因为某个损失函数设计得足够巧妙,而是因为它所试图捕捉的那个对象,即意义的结构本身就具备可以被几何化的性质。平滑性保证了邻域内的可推断性,流形假设保证了有效维度的可控性,这两者加在一起,意味着语义空间里存在着一种内禀的、低维的、光滑的几何结构,它不是 Embedding 模型发明的,而是 Embedding 模型发现的。
或者用一个更具体的说法:Word2Vec 没有创造”国王减去男人加上女人等于王后”这个关系。这个关系早就存在于人类语言的统计结构中,存在于几十亿句话的共现模式里,存在于人类几千年来使用这些词的方式里。Word2Vec 只是提供了一面足够灵敏的镜子,让这个本来就存在的结构显影了出来。
从这个角度看,Embedding 与其说是一种人工智能技术,不如说是一种测量仪器。望远镜没有创造星星,显微镜没有创造细胞,Embedding 模型也没有创造语义的几何性。它们做的事情是同一件:把一种本来就存在但肉眼不可见的结构,转换成了人类(以及机器)可以观察、度量和操作的形式。
而这件事之所以深刻,是因为它隐含着一个关于世界本身的断言:意义不是混沌的。 概念与概念之间不是以任意的、随机的方式散落的。它们有邻域,有距离,有方向,有可以被连续行走的路径。语义世界和物理世界一样,拥有自己的拓扑、自己的度量、自己的几何。
我们在第一节说过,科学的全部底气建立在一个赌注上:相似的原因倾向于产生相似的结果。现在我们可以看到,这个赌注的射程比我们当时以为的更远。它不仅适用于温度与密度、位置与海拔这些物理量之间的关系,也适用于词语与词语、概念与概念、意义与意义之间的关系。世界的局部平滑性不止是物理定律的性质,它似乎是结构本身的性质,任何足够丰富、足够有组织的系统,无论是物理的还是符号的,都倾向于表现出这种平滑性。
也许这才是 Embedding 最深层的意义。它不只是一种让检索变快、让推荐变准、让 RAG 成为可能的工程工具。它是一个来自数学的证据,表明我们所栖居的这个世界——包括我们用语言和概念建造的那个精神世界——在最根本的层面上,是有结构的、可度量的、几何的。
而这件事,值得我们感到一点点惊奇。