在大模型时代,「上下文」这个词被频繁提起,却常常在讨论中被过度简化。我们可以先退后一步,问一个更根本的问题:上下文究竟是什么?
对于人类而言,上下文是我们理解世界时的那层看不见的背景幕布。它是两个老朋友聊天时无需言明的共同经历,是团队讨论项目时每个人脑海中关于前情的默契假设,是你读到这句话时,前面所有文字在你意识中留下的痕迹对当下理解的持续塑造。我们和他人进行的每一次对话、每一项研究、每一段协作,都依赖这种「默示」的共享认知来避免从零开始反复解释同一件事,让思考得以保持连续性和方向感。
对于大模型来说其实也差不多,只是这些概念被具象成了 system prompt、聊天历史、外部工具调用结果,以及各种临时拼接进来的检索信息。所有这些片段共同构成了模型的“工作记忆”:它在多大程度上理解自己现在身处哪一个任务链条、面对的是谁、需要延续的目标是什么,这些都取决于当前被送进上下文窗口的内容。
那么问题来了:既然上下文如此重要,为什么不干脆把所有相关信息都塞进去呢?
答案藏在 Transformer 这个架构的底层设计里。当模型处理一段文本时,它需要让每一个词都去关注上下文中的所有其他词,计算它们之间的关联强度。这种全局注意力机制赋予了模型强大的理解能力,但也埋下了一个代价高昂的伏笔:当上下文长度翻倍时,计算量会翻到四倍;长度增加到十倍,计算量就变成一百倍。
从数学上看,假设输入序列长度为 ,每个词被表示为一个 维的向量。标准的自注意力需要计算一个 的注意力权重矩阵,其中每个元素 表示第 个词对第 个词的关注程度:
这里 (查询)、(键)、(值)都是 的矩阵。关键在于 这一步:两个 的矩阵相乘,得到一个 的矩阵,计算复杂度为 。由于 通常是固定的模型超参数,真正随输入规模变化的是 这一项。
这就是为什么复杂度被称为「二次方」级别。当序列长度 从 1000 增长到 10000 时, 从 100 万跃升到 1 亿,计算量增加了整整两个数量级。而存储那个 的注意力矩阵同样需要 的显存,这往往成为实际部署中更早触及的瓶颈。
想象一个圆桌会议:如果只有四个人参加,彼此交流起来轻松自如,每个人只需要关注另外三个人的发言。但当人数增加到四十人,每个人需要同时追踪的对话线索就变成了三十九条,整个房间里的信息交换复杂度呈几何级数攀升。Transformer 面对的正是这样的困境。
这意味着,哪怕硬件算力在持续进步、上下文窗口在不断扩大,我们永远无法通过「暴力堆料」的方式彻底解决问题。把一本五百页的技术手册完整塞进上下文,带来的可能是响应时间从两秒变成二十秒,推理成本从几分钱飙升到几块钱,而模型的注意力反而在信息的海洋中被稀释,重要的细节淹没在无关的噪声里。
正因如此,「如何更好地管理上下文」成为了从2022年12月 ChatGPT 发布以来整个业界在持续攻关探索的主要方向之一:
一方面,我们希望模型在长周期的协作中维持稳定的人设、偏好和目标感,能记住之前的决策和约定;
另一方面,算力与上下文窗口依然有限,生搬硬塞更多文本只会带来成本飙升、干扰增多、推理变钝。真正困难的地方在于,什么该被长期保留,什么只作为一次性线索,什么需要在多轮交互中逐步抽象成结构化的知识与技能。
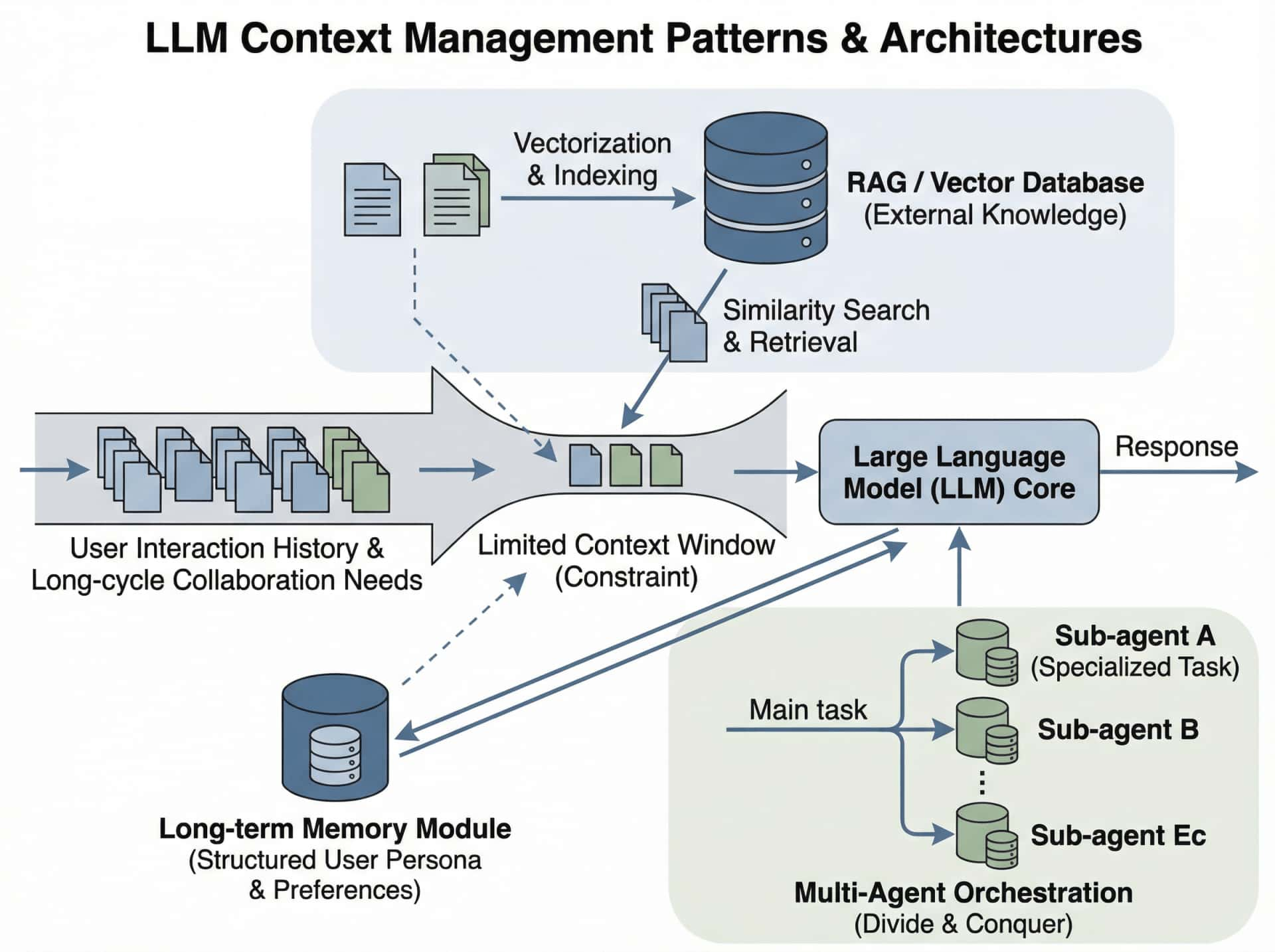
过去几年,业界对上下文管理的探索当然是卓有成效且进展迅速的,逐渐形成了几条相对清晰的技术路径,主要可以归纳为:
- 扩大窗口、做检索增强,将更多文档向量化之后按相似度塞回对话
- 配合少量长期记忆 memory 工具,把用户偏好和基本资料存起来
- 做特化 subagent,分拆任务复杂度,分而治之管理上下文
图源:香蕉生的
我们将会在下文各个分析其思路。
一、当前业界的几种主流上下文管理方向
1.检索增强生成(RAG):让模型学会查资料
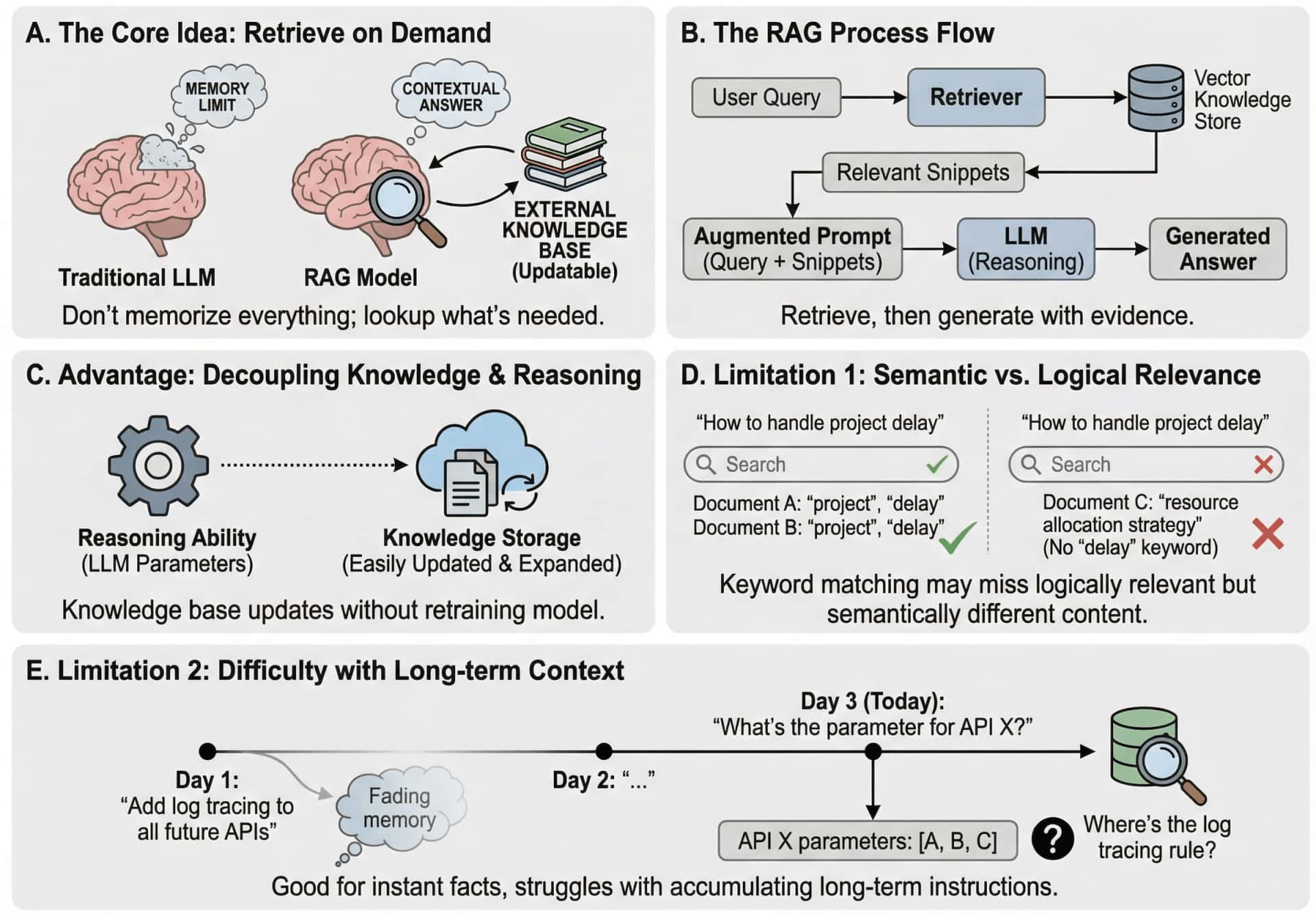
RAG 的核心思想其实非常朴素:既然上下文窗口装不下所有信息,那就别装了,需要什么再去查。
这个思路模仿的是人类专家的工作方式。一位资深律师不会把所有法条都背在脑子里,但他知道在遇到具体案件时去哪里找到相关的判例和条文。RAG 赋予了大模型类似的能力:当用户提出问题时,系统先从外部知识库中检索出可能相关的文档片段,然后把这些片段和用户的问题一起送进模型,让模型在「有据可查」的前提下生成回答。
RAG 的优势在于它将「知识存储」和「推理能力」解耦了:模型本身不需要记住所有细节,它只需要具备理解和整合信息的能力。知识库可以随时更新、扩展,甚至可以针对不同领域构建专门的知识源,而模型的参数不需要任何改动。
然而 RAG 的局限性也同样明显。检索的质量严重依赖于向量化表示和相似度匹配的准确性,而语义相似并不总是等于逻辑相关。一个用户问「如何处理项目延期」,检索系统可能返回一堆包含「项目」和「延期」关键词的文档,但真正有价值的可能是某次会议纪要中关于资源调配策略的讨论,而这段内容在字面上可能完全没提到「延期」二字。
从原理角度,RAG 本质上是一种「即时查询」的机制,它擅长回答事实性的问题,但难以处理需要长期上下文积累的推理任务。它能告诉你某个API的参数是什么,但很难记住你三天前说过「以后所有接口都要加上日志追踪」这样的持续性约定。
图源:香蕉生的
因此,业界顺理成章地探索出了第二个方向:分层记忆系统。
2.分层记忆系统
此事在 Lapis0x0 大人的博文《浅谈ChatGPT的记忆实现机制 兼论工程端记忆设计》中亦有记载
如果说 RAG 是让模型学会查资料,那么记忆系统则是让模型学会「记事情」。
这个方向的设计灵感直接来源于认知科学对人类记忆的研究。心理学家早就发现,人类的记忆并非单一的存储系统,而是由工作记忆、短期记忆和长期记忆等多个子系统协同运作的复杂网络。每个子系统有不同的容量限制、存储时长和提取机制。
映射到AI系统中,这种分层设计就变成了:
工作记忆对应的是当前对话轮次中的即时上下文,它容量最小但访问最快,直接影响模型当前的推理。你刚才说的那句话、你正在编辑的这段代码,都活跃在这个层面。
短期记忆通常覆盖一个会话周期或一个任务阶段。它存储的是「这次我们在讨论什么」「用户刚才提出了哪些要求」这类信息。很多产品中的「对话历史」功能就属于这个层面,但更精细的实现会对历史内容进行摘要和压缩,而非无限塞原始对话记录到上下文(大家的钱包和 GPU 都受不了)。
长期记忆则是跨越会话、跨越任务的持久化存储。它保存的是用户的偏好设定、项目的核心约定、历次协作中提炼出的经验教训。这些信息有的会在每次对话中都被加载,有的会在系统判断其相关时才被调取,具体看各家的实现策略。
分层信息系统的设计好就好在它承认了一个现实:不是所有信息都同等重要,也不是所有信息都需要同等的可访问性。通过将信息分流到不同层级,系统可以在有限的上下文窗口内维持更好的信息密度和相关性。
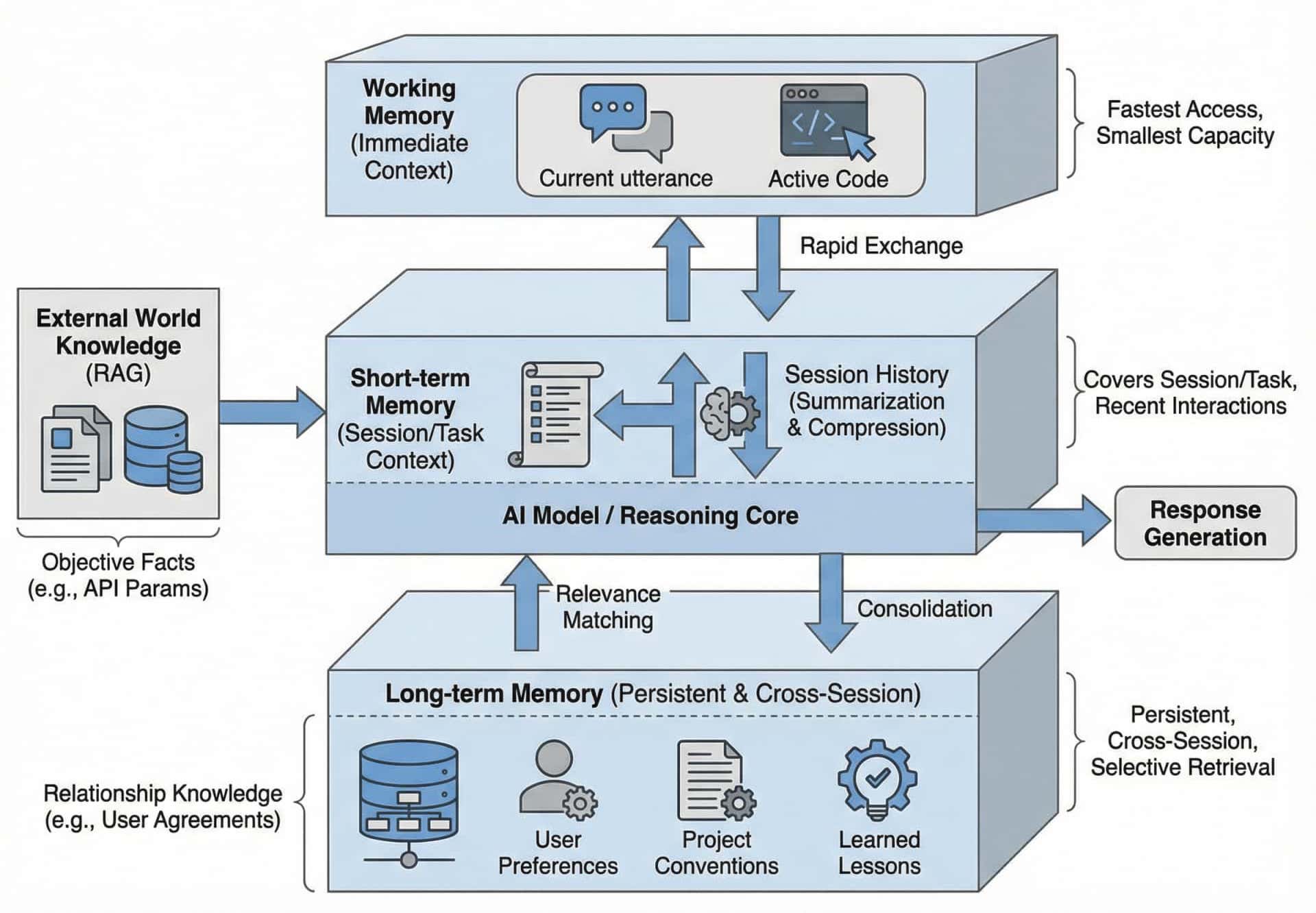
以 ChatGPT 为例,OpenAI 构建了一套相当精细的用户画像系统:显式保存的记忆条目、隐式提取的行为洞察、响应风格偏好、近期对话摘要,再加上各种交互元数据。这些信息被结构化地组织起来,在每次对话开始时根据语义相关性动态注入到系统提示中。用户看到的是「ChatGPT 记得我喜欢咖啡」,实际发生的是系统在背后偷偷提醒模型「这位用户喜欢咖啡」。
在记忆系统的探索上,市面上有非常多出色的开源项目,例如 LangChain 的 Memory 模块、LlamaIndex 以及专门针对长短期记忆优化的 Mem0 和 Zep 等
记忆系统的设计也是一项非常复杂的系统工程:什么信息应该从短期记忆「固化」到长期记忆?什么时候应该「遗忘」过时的内容?如何在提取记忆时平衡相关性和新鲜度?这些问题目前都还没有标准答案,不同的产品和框架给出了各异的策略。
不过,跳出这些技术细节,从功能定位的角度来看,记忆系统和前面提到的 RAG 其实在解决同一个问题的不同侧面,是一体两面的。RAG 擅长处理世界知识,是那些存在于外部文档、数据库、知识图谱中的客观信息;而记忆系统更擅长处理关系知识,那些在持续交互中积累的、关于「我们之间」的默契和约定。一个成熟的系统往往需要两者协同工作:RAG 告诉模型”这个 API 的参数是什么”,记忆系统告诉模型”用户三天前说过以后所有接口都要加日志追踪”。
无论是 RAG 还是记忆系统,它们本质上都还是在「单个模型」的框架内做优化。当任务复杂度继续上升,当我们需要处理的不再是简单的问答而是多步骤、多领域的协作流程时,另一条路径开始显现出它的价值。
3.子代理架构(Sub-Agent):通过分工实现上下文隔离
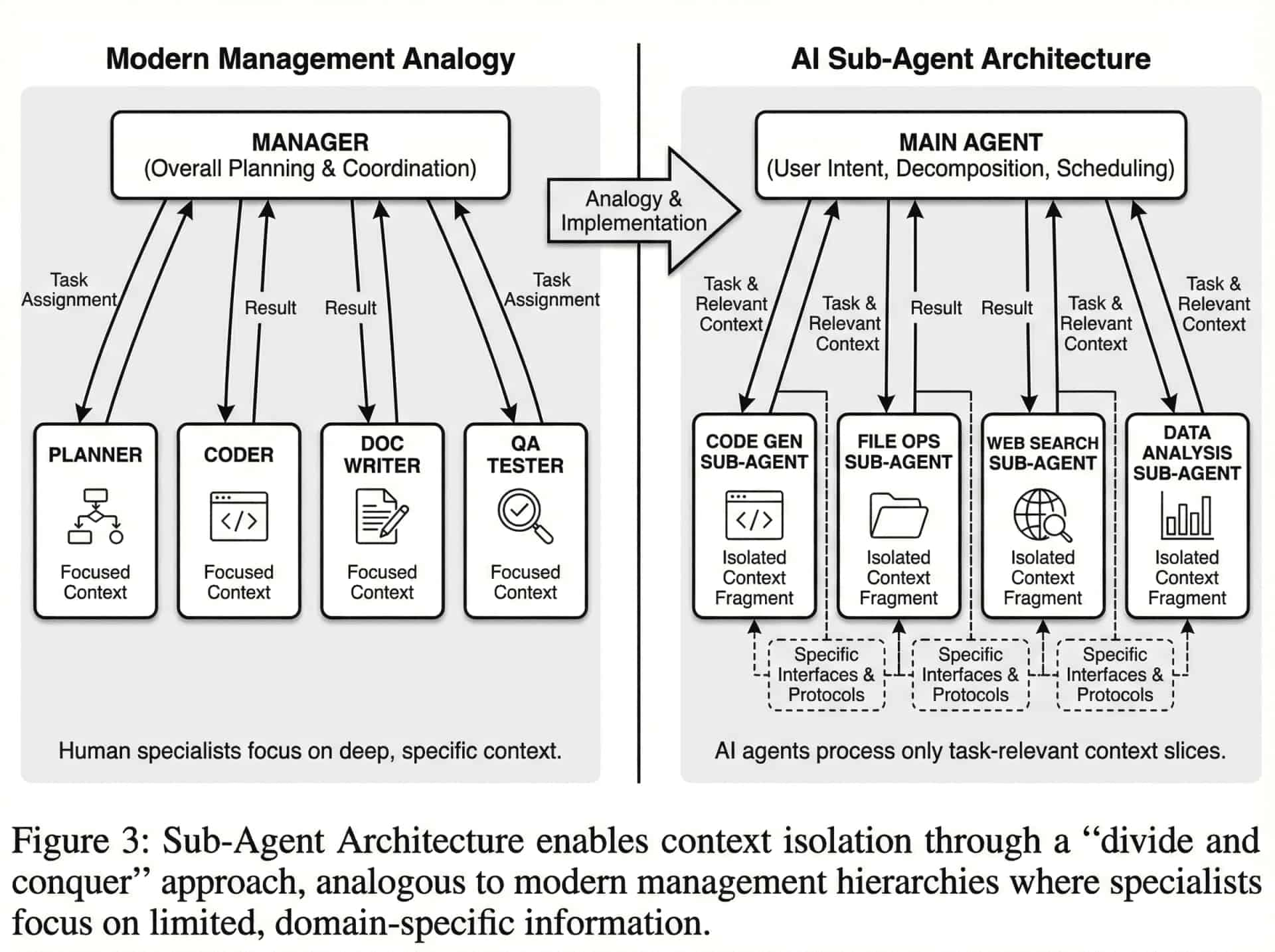
前面两种方法都在试图优化「单个模型如何更好地利用上下文」,而子代理架构则换了一个思路:既然一个模型的上下文有限,那就让多个模型分工合作,每个模型只需要关注自己负责的那部分上下文,即分而治之。
这种设计的灵感来源更像是现代管理学:当一个复杂项目需要处理时,作为一位管理者,你不会让一个人记住所有细节、完成所有任务。更有效的方式是设立不同的角色(专员)——有人负责整体规划,有人专注代码实现,有人处理文档撰写,有人进行质量检查。每个角色只需要掌握自己领域内的深度上下文,通过明确的接口和协议与其他角色协作。
在AI系统中,这就演变成了「主代理 + 多个专业子代理」的架构。主代理负责理解用户意图、分解任务、协调调度;子代理各自专注于特定领域,比如代码生成、文件操作、网络搜索、数据分析等。当主代理判断某个任务需要特定能力时,它将相关的上下文片段传递给对应的子代理,由子代理完成具体工作后返回结果。
在工程实践层面,开源社区已经有不少具有代表性的开源项目。面向基础编排能力的,有 LangGraph 和它的 Swarm 扩展,他们把每个代理抽象成图上的节点,通过状态机和有向图来控制谁在什么时候接过话语权;CerwAI 则是把一组代理组织成一个“crew”,通过角色设定和 Flow 抽象来管理多代理之间的上下文共享与任务分派。
如果从“管理学类比”的角度看,MetaGPT 直接把系统设计成一个小型软件公司,内部有产品经理、架构师、项目经理、开发和测试等不同角色,输入一句需求,就会沿着既定流程完成需求拆解、技术方案、代码实现再到文档输出,非常直观地体现出“每个子代理只掌握本职领域的深度上下文,通过清晰的接口协作”的思想。类似的还有 ChatDev 等项目,它们都把复杂的软件开发拆成若干彼此配合的专员代理,从而在流程上天然形成上下文隔离和失败隔离。
最后,在具体场景里,也有一些项目把子代理架构深扎到某个垂直领域。CAMEL 及其衍生框架把多代理当作研究对象,重点探索“多角色协作如何在复杂任务上表现得更好”,是最早一批系统性做 LLM 多代理实验的社区之一。IDE 的开源编程 Agent 插件 Kilo code 也做的很不错,值得推荐。
这种架构带来的好处是多方面的。首先,每个子代理的上下文可以高度专业化,不会被无关信息干扰。一个专门处理数据库查询的子代理,它的上下文里就只有数据库模式、查询需求和相关的领域知识,不会混入用户偏好设置或项目管理约定。其次,不同子代理可以并行工作,提升整体效率。第三,失败隔离:一个子代理的错误不会污染其他子代理的上下文和状态。
当然,这种架构也引入了新的复杂性。代理之间如何有效通信?主代理如何判断应该调用哪个子代理?任务分解的粒度如何把握?多个子代理的输出如何整合成连贯的最终结果?这些都是工程实现中需要仔细权衡的问题。
二、那么,Skills 是什么?
我们姑且可以把上一节讲的三种路径看成「如何给模型喂上下文」的三种策略,而 Skills 更像是在这些策略之上又抽象出来的一层组织形式。Skills 关心的不是单条对话、单个记忆片段,而是如何把一整套可复用的工作方法固化下来,在需要时再整块挂载进上下文。
在当前业界语境下,Skills 通常指这样的一种能力单元,最早由 Anthropic 提出,它被实现为一个文件夹,里面放着说明书、参考资料,有时还包含脚本;支持Skills 的智能体可以合适的时候把对应 Skills 的内容加载进自己的上下文,把自己暂时变成某个领域的熟练工。
OpenAI 在 Codex 里对 Skills 的定义是:Skills 让团队可以把组织里的经验和流程沉淀成可复用、可共享的工作流,让 Codex 在不同人、不同仓库、不同会话中都能保持一致的行为。 每个 Skill 至少有名字、描述和一套说明,Codex(或者别的什么 Agent)默认只把名字和描述注入上下文,只有显式调用时才把完整说明展开;Anthropic 的 Claude Skills 则是把它解释成「写在 Markdown 文件里的超级提示词」,再配上一些参考资料和脚本,让 Claude 像拿到了一本本可以随时翻开的业务手册。
从这些实现里抽象出来,可以把 Skills 看成满足三点的东西:
- 它是结构化的上下文包(package),是一个有文件结构的小型知识库,核心通常是一份 Skill.md 或 SKILL.md,里面写清楚任务定义、语气风格、操作步骤、注意事项,旁边可以挂各种 PDF、示例模板、脚本等。
- 它是可复用的流程单元,是程序化的 playbook,强调可重复执行、结果稳定、可以不断迭代;有人把 Skills 类比成团队的 SOP:你把十几二十年的做事方式打包进一个文件夹,让模型每次照着这套做。
- 它是按需加载的能力扩展。无论是 Codex 的 Skills,还是 Claude Skills,抑或 VS Code / Copilot 里的 Agent Skills,设计上都强调「渐进式暴露」:先只把 Skill 的元信息丢给模型,让它知道「有这么个工具」,只有当当前任务真的需要时,才把完整说明、脚本和资源一点点塞进上下文里。
1.它解决的到底是什么问题?
如果只从产品交互层面看,Skills 解决的是一个很多人已经习惯到麻木的问题:重复说人话。
在 Claude Skills 的介绍里,官方和第三方文章反复举一个例子:你有一套公司内部的写作规范,每次让 AI 写新闻稿、周报、提案前,都要先贴一大段要求;有了 Skill 之后,把这些要求写进 Skill.md,再配上历史范文,之后只要说「帮我写一份本周市场回顾」,模型自己就会加载那套规范,套模板、控语气。VS Code或者各种 AI IDE 里的 Agent Skills 也是类似思路:开发者把测试流程、部署步骤、日志分析方法写成一个技能,Copilot 在需要时调用,省掉反复讲解「我们项目是怎么写单测、怎么发版」这样的口水。
当然,如果只是到这里,那 Skills 看起来和以前的各种 system prompt 套壳助手 & 斜杠预制命令没区别了,都是”把常用指令存起来方便调用”。但如果再往工程架构深究一下,会发现 Skills 真正在处理的是一个更难啃的问题:上下文管理。
在这里,被迫重复说人话只是症状,病根在于用户每次都得把完整的背景信息塞进对话窗口。一份风格指南可能几千字,每轮都贴进去,既麻烦费钱又挤占模型的注意力。Skills 的做法是把 “我具备这项能力”的声明和”这项能力的完整说明”拆开存放,只在确实需要时才展开详细内容,可以显著节省 token,也减轻注意力扩散的问题。这个设计顺便也回应了另外两个长期困扰 AI 应用的问题:
第一,程序性知识的碎片化。RAG 可以查文档,Memory 可以记偏好,Sub-agent 可以分角色,但「如何做事」这类程序性知识常常散落在无数对话、文档和隐性经验里。Skills 提供了一个显式的容器,把流程本身变成 routine:从「记住这件事」变成「记住如何做这件事」。
第二,跨产品、跨团队的一致性问题。Agent Skills 标准刻意强调可移植性:同一套 Skill 文件夹既可以被 Claude 用,也可以被 Copilot 或其他兼容代理加载;企业可以把一套合规检查、品牌规范、风控流程打包,在不同 AI 产品间共享,而不用为每个交互 UI 单独维护一份提示词。
2.一个好的 Skills 应该是什么样的?
前面我们提到,Skill 本质上是一个具备文件结构的小型知识库。它的核心是一份 SKILL.md 文件,用于记录元数据并指导 Agent 如何执行特定任务;除此之外,还可以包含脚本、模板、参考文档等辅助资源。一个典型的 Skill 文件夹结构如下:
my-skill/├── SKILL.md # 必需:元数据 + 操作指令├── scripts/ # 可选:可执行的代码脚本├── references/ # 可选:参考文档└── assets/ # 可选:模板、样例资源在实际执行中,Skills 采用渐进式信息呈现机制来实现高效的上下文管理:
- 发现阶段:启动时,Agent 仅加载各技能的名称与简短描述。这一阶段的上下文开销极低,只包含判断技能适用性的必要信息。
- 激活阶段:当用户的任务需求与某项技能的描述匹配时,Agent 将完整的
SKILL.md载入上下文,获取详细的操作指令。 - 执行阶段:Agent 遵循指令逐步执行,按需加载引用文件或调用捆绑的代码脚本。
这种”按需加载”的设计意味着:你可以注册数百项技能,而实际占用的上下文窗口始终保持精简。
光看理论结构可能还是有点抽象,不如我们拆解一个真实案例。以下是 Anthropic 官方提供的 docx 文件处理 Skill,它演示了一个成熟 Skill 的典型写法。
这个 Skill 的文件结构如下:
docx/├── SKILL.md # 核心指令文件(197行)├── LICENSE.txt # 许可协议├── docx-js.md # docx-js 库详细文档├── ooxml.md # OOXML 操作详细文档├── scripts/│ ├── document.py # Python 文档操作库│ ├── utilities.py # 工具函数│ └── templates/ # XML 模板文件│ ├── comments.xml│ ├── commentsExtended.xml│ └── ...└── ooxml/└── scripts/├── unpack.py # 解包 docx 文件├── pack.py # 打包 docx 文件└── validate.py # 验证文档结构还挺复杂的吼(
让我们先看 SKILL.md 的 YAML 头部:
---name: docx
description: "Comprehensive document creation, editing, and analysis with support for tracked changes, comments, formatting preservation, and text extraction. When Claude needs to work with professional documents (.docx files) for: (1) Creating new documents, (2) Modifying or editing content, (3) Working with tracked changes, (4) Adding comments, or any other document tasks"
license: Proprietary. LICENSE.txt has complete terms---description 字段是整个 Skill 的索引,在 Agent 启动时,所有已安装的 Skills 的 name 和 description 都会被加载到上下文中,但 SKILL.md 的正文内容此时还没有被读取。
- 如果你有 20 个 Skills,每个 description 平均 100 tokens,那么启动成本只有 2000 tokens
- 相比之下,如果直接加载所有 Skills 的完整内容(平均每个 5000 tokens),启动成本将高达 100,000 tokens
在实践中,Agent 会根据用户的任务需求,匹配 description 来决定是否激活某个 Skill。只有当 Agent 判断”用户想要处理 .docx 文件”时,才会完整读取这个 SKILL.md 的正文部分。
2.1 决策树式的工作流指导
进入 SKILL.md 的正文部分,我们会看到一个清晰的决策树结构:
## Workflow Decision Tree
### Reading/Analyzing ContentUse "Text extraction" or "Raw XML access" sections below
### Creating New DocumentUse "Creating a new Word document" workflow
### Editing Existing Document- **Your own document + simple changes**Use "Basic OOXML editing" workflow- **Someone else's document**Use **"Redlining workflow"** (recommended default)- **Legal, academic, business, or government docs**Use **"Redlining workflow"** (required)这个设计体现了 Skill 的第一个核心原则:适度的自由度控制。对于”阅读文档”这种相对简单的任务,Skill 只提供了工具推荐(用 pandoc 转 markdown),给 Agent 较高的自由度;但对于”编辑文档”这种容易出错的复杂任务,Skill 明确规定了不同场景下应该使用的工作流,将自由度降低到最小,确保操作的可靠性。
正如 skill-creator 这个 meta-skill 中所说:
Match the level of specificity to the task’s fragility and variability: High freedom (text-based instructions): Use when multiple approaches are valid, decisions depend on context, or heuristics guide the approach. Low freedom (specific scripts, few parameters): Use when operations are fragile and error-prone, consistency is critical, or a specific sequence must be followed.
将具体程度与任务的脆弱性和可变性相匹配: 高自由度(基于文本的指令):当多种方法均有效、决策取决于语境或由启发式方法指导时使用。 低自由度(特定的脚本,参数较少):当操作脆弱且易错、一致性至关重要或必须遵循特定顺序时使用。
2.2 分层文档引用
SKILL.md中还有这样的指令:
### Creating New Document1. **MANDATORY - READ ENTIRE FILE**: Read [`docx-js.md`](docx-js.md)(~500 lines) completely from start to finish.这里引入了 Skill 的第二层加载机制:reference 文件。
docx-js.md 是一个详细的技术参考文档,包含了使用 docx-js 库创建 Word 文档的完整 API 说明和示例代码。它有 500 行左右,如果一开始就加载到上下文中,会占用大量 tokens;但如果不提供这些信息,Agent 又无法正确使用这个库。Skills 的解决方案是:在 SKILL.md 中只保留”什么时候需要读什么文档”的导航信息,具体的技术细节放在单独的 reference 文件中。 只有当 Agent 真正需要创建文档时,才会去读取 docx-js.md。
这种分层设计的核心思想就是渐进式上下文披露,将“能力的声明”和“能力的细节”在原本已经模块化的前提下进一步解耦,使得一个 Skill 具备复杂、多样的能力,同时保持较低的上下文开销。
2.3 脚本捆绑:将确定性操作封装到代码中
在 docx skill 的文件结构中,我们看到了 scripts/ 目录,里面包含了多个 Python 脚本。让我们看看这些脚本的作用:
# scripts/document.py 的部分代码
class Document:
"""Library for working with Word documents: comments, tracked changes, and editing."""
def add_comment(self, start, end, text):
"""Add a comment to the document"""
# ... 复杂的 XML 操作逻辑
def suggest_deletion(self, node):
"""Suggest deletion with tracked changes"""
# ... 精确的 OOXML 标记插入这些脚本解决的问题是:某些操作太容易出错,不应该让 LLM 每次都从头生成代码。
想象一下,如果没有这些脚本,每次 Agent 需要在 Word 文档中添加批注时,都要:
- 解析 OOXML 的 XML 结构
- 生成符合规范的
<w:comment>元素 - 在正确的位置插入引用标记
- 更新
comments.xml文件 - 确保所有 ID 不冲突
这个过程有太多细节需要处理,LLM 很容易在某个环节出错。但有了 document.py 提供的 add_comment() 方法,Agent 只需要调用一个函数就能可靠地完成操作。
这就是 Skill 的第三个核心能力:通过脚本封装提供确定性保证。
此外,这个 Skill 还使用了工作流拆分、验证闭环和提供最佳实践指导等高级 prompt 方法,但我懒得写了,此处暂且不表。
3.Skills 的设计哲学
通过分析 Anthropic 的 Skills 实现,我们可以提炼出几个核心的设计哲学:
其一,上下文是公共资源。
在 skill-creator 这个 meta-skill 中,有一段话让人印象深刻:
The context window is a public good. Skills share the context window with everything else Claude needs: system prompt, conversation history, other Skills’ metadata, and the actual user request. Default assumption: Claude is already very smart. Only add context Claude doesn’t already have. Challenge each piece of information: “Does Claude really need this explanation?” and “Does this paragraph justify its token cost?”
上下文窗口是一种公共资源。 技能与 Claude 所需的其他所有内容共享上下文窗口:系统提示词、对话历史、其他技能的元数据以及实际的用户请求。 默认假设:Claude 已经非常聪明。 仅添加 Claude 尚未掌握的内容。质疑每一条信息:“Claude 真的需要这个解释吗?”以及“这段文字的价值是否对得起它的 Token 开销?”
即,我们应当把上下文当做稀缺的公共资源来精心管理;这意味着:
- 不要重复 Claude 已经知道的东西。Claude 已经知道什么是 JSON、什么是 HTTP 请求,你不需要在 Skill 里解释这些基础概念。
- 用例子代替解释。一个好的代码示例可能比 100 字的描述更节省 tokens,也更容易理解。
- 分层披露,延迟加载。只在真正需要时才加载详细信息。
- 定期审查和精简。随着模型能力的提升,一些原本需要的说明可能已经不再必要。
第二,自由度是根据任务脆弱性动态调整的。
我们在 docx skill 中看到了这种设计:
- 对于”读取文档”这种低风险操作,只提供工具建议,给 Claude 高度自由
- 对于”添加修订标记”这种高风险操作,提供详细的步骤和示例,严格限制自由度
Think of Claude as exploring a path: a narrow bridge with cliffs needs specific guardrails (low freedom), while an open field allows many routes (high freedom).
这个比喻很有趣,在 Skills 的设计中脆弱的操作(如 OOXML 修改)需要”窄桥”,需要我们提供脚本、详细步骤、示例代码;而灵活的任务(如文档内容分析)需要”开阔地”:只提供目标和工具,让 Claude 自主决策。
其三,Skills 不是文档,是操作手册。
一个常见的误区是把 Skill 当作”用户手册”或”API 文档”来写。但 Anthropic 的 Skills 明确强调:
A skill should only contain the information needed for an AI agent to do the job at hand. It should not contain auxiliary context about the process that went into creating it, setup and testing procedures, user-facing documentation, etc.
也就是说:
- ❌ 不要写 README.md 解释这个 Skill 是干什么的(那是给人看的)
- ❌ 不要写 CHANGELOG.md 记录版本历史(AI 不关心历史)
- ❌ 不要写 INSTALLATION_GUIDE.md 解释如何安装(那是部署阶段的事)
- ✅ 只写 SKILL.md,里面只放”如何完成任务”的操作指令
这种”极简主义”的设计哲学,确保了 Skills 的纯粹性:它是给 AI 的 playbook,不是给人的说明书。
其四,好的 Skills 是从真实使用中迭代出来的。
skill-creator 中的流程设计很有启发性:
## Skill Creation Process
1. Understand the skill with concrete examples2. Plan reusable skill contents (scripts, references, assets)3. Initialize the skill (run init_skill.py)4. Edit the skill (implement resources and write SKILL.md)5. Package the skill (run package_skill.py)6. **Iterate based on real usage**最后一步”基于真实使用迭代”被单独列出,强调了一个重要观点:Skills 不是设计出来的,是用出来的。
只有在真实场景中使用 Skill,你才能发现哪些说明其实是多余的、哪些步骤容易出错需要更详细的指导、哪些操作应该封装成脚本和哪些参考文档应该拆分或合并。
这种”持续迭代”的理念,让 Skills 成为一个活的、不断进化的知识库,而不是一次性写完就束之高阁的静态文档。
三、上下文管理的未来图景
目前我们讨论的所有方案,无论是RAG的知识库、Memory的记忆条目,还是Skills的能力包,本质上都是人类预先设计好,AI被动执行的模式。人类决定什么该被记住、什么该被检索、什么流程该被封装成Skill。
但如果我们观察人类专家是如何积累能力的,会发现:专家的技能不是被”配置”出来的,而是在实践中涌现出来的。一个资深律师不会先背诵完所有SOP再开始工作,而是在处理一个又一个案件的过程中,逐渐提炼出自己的工作方法。
这指向了上下文管理的下一个演化方向:Agent能否从交互中自主习得新的Skills? 当一个Agent反复处理类似的任务,它能否自己识别出”这是一个值得固化的流程”,然后自动生成对应的SKILL.md?
一些前沿探索已经在触碰这个边界。
早在三年前,Voyager 项目就已让Agent在Minecraft中通过代码库的形式积累可复用的技能;一些研究者开始尝试让LLM从对话历史中自动提取”程序性知识”,并将其结构化为可复用的模块;在 Yunjue-Agent中,我们也可以看到 Agent 在复杂任务中完全可以自己制造一大批 Skills 工具然后进一步螺旋升天自我强化去解题,可以像人那样持续学习,而迭代速度则远快于人类……
把视野拉远一点,我们会发现上下文管理这件事正在发生新的方法论革命。最早期的做法是”塞”,把所有可能相关的信息一股脑塞进提示词里,然后祈祷模型能从中找到有用的部分;后来演变成”取”,通过 RAG 和记忆系统,在需要时精准提取相关片段;现在 Skills 代表的是”挂载”,把预先打包好的能力模块按需加载;而未来的方向很可能是”生长”,让 Agent 在持续交互中自发地积累、提炼、更新自己的能力库。
当我们讨论”管理上下文”的时候,本质上是在讨论如何让模型在有限的注意力资源下,把认知焦点放在最关键的地方。RAG 解决的是”世界知识的焦点”问题,Memory 解决的是”关系知识的焦点”问题,Skills 解决的是”程序知识的焦点”问题,而子代理架构则是通过分工把复杂任务拆解成多个更容易聚焦的子问题。
从这个角度看,未来的上下文管理系统很可能会呈现一种更加有机的形态。想象一个 Agent,它的能力库像一棵不断生长的树:每次成功完成一个复杂任务,它都会把其中可复用的部分萃取出来,形成新的枝叶;那些长期不被调用的能力会逐渐休眠,被压缩成更紧凑的索引;而那些频繁使用的核心技能则会被反复打磨,变得越来越精炼高效。这棵树不需要人类园丁每天修剪,它自己知道哪些枝条该保留、哪些该剪去、哪些该合并。
其实目前 gpt5.2codex 已经有点这种味道了,每一轮交互模型都会自动压缩上下文,舍弃掉哪些不必要的冗余信息,虽然我们尚不知道它是如何实现的
当然,这幅图景目前还只是一种可能性,而非现实。在真正落地之前,还有大量的技术挑战需要攻克:如何让模型可靠地识别”值得固化”的模式?如何防止自动生成的 Skills 质量退化或相互冲突?如何在保持灵活性的同时确保行为的一致性和可预测性?这些问题都没有现成的答案。
但有一点是确定的:在模型能力不断提升、上下文窗口持续扩大的今天,“如何更好地管理上下文”这个问题并没有变得更简单,反而变得更加复杂更加关键。
无论是对人类还是对AI而言,能够在信息的洪流中准确地知道”现在该关注什么”,才是一切有效协作的前提。
本文探索的 Anthropic Skills 仓库:https://github.com/anthropics/skills
Agent Skills 规范:https://agentskills.io