内容时效性提醒"本篇博客完成日期距现在已大于一年,内容可能已过时,相关技术、政策或情况可能已发生变化,建议读者查证最新信息。"
项目文件已上传至Github和我自己的公开仓库。
一、背景介绍
2024.10.22:本篇博文的展示代码已经落后于GitHub库代码,但我懒得写一篇新的博客来解析对应GitHub库了,实际上主要的实现方式路径都差不多,如果你想训练自己的分类模型而不想究其原理,直接fork库即可
事情的起因是这样的:
我看到喜欢的图都会直接保存到手机里(猫猫狗狗、各种群友分享的网上搜集的蔚蓝档案图、壁纸等),但是这些图片又会和我繁杂的各种随手截图,拍照留下的笔记等混到一块,每次整理上传到云端都需要我一张一张的分类判别,挺烦人的。
——为什么不直接用ai来识别呢?
经过一番广泛的调查与试错之后,我选择了ResNet。
ResNet,全称Residual Network(残差网络),是由何凯明(Kaiming He)、张祥雨(Xiangyu Zhang)、任少卿(Shaoqing Ren)和孙剑(Jian Sun)在2015年提出的深度学习架构。他们在同一年的ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 中取得了多项任务的第一名,包括图像分类和物体检测。
ResNet的主要创新点在于它引入了一种特殊的网络结构——残差块(Residual Block),这使得深度神经网络能够有效训练更多的层而不遭受性能退化的问题。在传统深度网络中,随着网络深度的增加,训练变得越来越困难,可能会遇到梯度消失或梯度爆炸问题,以及所谓的“退化”现象,即更深的网络表现反而不如较浅的网络。
中译中:好用皮实效果好。
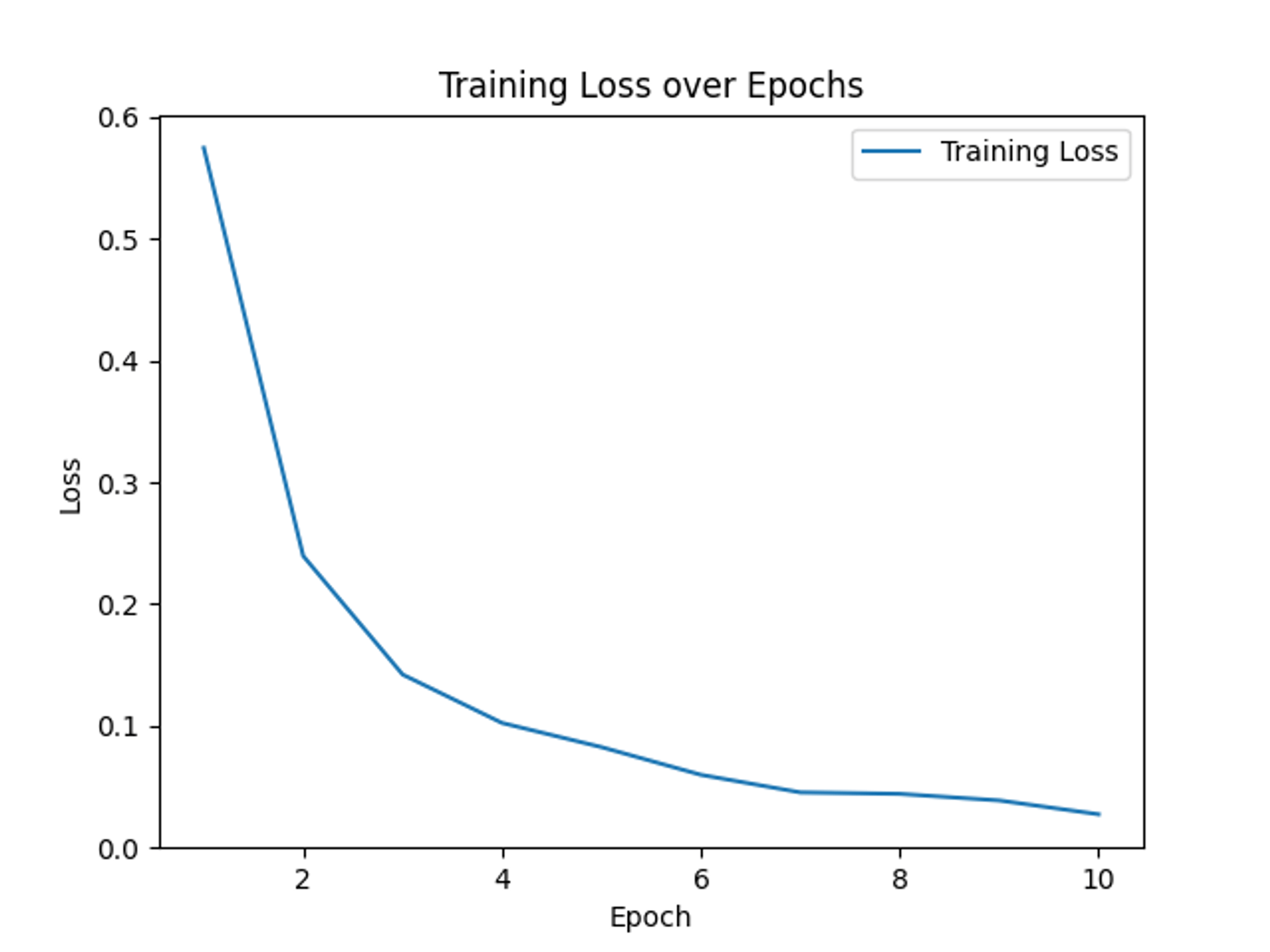
考虑到手上MacBook air的羸弱性能,我预训练的模型用的是ResNet-18,训练数据集一共分了四类:‘a.美少女’, ‘b.截图与杂图’, ‘c.动物’, ‘d.漫画’,一共大概六百张图片。训练跑了10个epoch,训练用时差不多10min(没有用Apple自己的mps加速框架),实际效果非常不错,准确率在95%左右。
二、完整代码
1.模型训练
import torchimport torchvisionimport torchvision.transforms as transformsfrom torch.utils.data import DataLoader, Datasetfrom torchvision.datasets import ImageFolderfrom torchvision.models import resnet18from PIL import Imagefrom tqdm import tqdmimport matplotlib.pyplot as plt
Image.MAX_IMAGE_PIXELS = None
# 数据预处理transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])
# 加载数据集dataset = ImageFolder(root='xxx/dataset', transform=transform)dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# 使用本地的预训练ResNet模型model = resnet18()state_dict = torch.load('models/resnet18-f37072fd.pth')model.load_state_dict(state_dict)
# 获取类别数量num_classes = len(dataset.classes)
# 修改最后一层以适应新的分类任务num_ftrs = model.fc.in_featuresmodel.fc = torch.nn.Linear(num_ftrs, num_classes)
# 训练模型criterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
num_epochs = 10 # 根据需要调整
# 记录每个epoch的loss值loss_values = []
for epoch in range(num_epochs): epoch_loss = 0.0 with tqdm(total=len(dataloader), desc=f'Epoch {epoch+1}/{num_epochs}') as pbar: for inputs, labels in dataloader: optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() epoch_loss += loss.item() pbar.set_postfix({'loss': epoch_loss / (pbar.n + 1)}) pbar.update(1)
avg_loss = epoch_loss / len(dataloader) loss_values.append(avg_loss) print(f'Epoch {epoch+1}/{num_epochs}, Loss: {avg_loss}')
# 保存模型torch.save(model.state_dict(), 'model.pth')
# 绘制并保存loss值图表plt.figure()plt.plot(range(1, num_epochs + 1), loss_values, label='Training Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.title('Training Loss over Epochs')plt.legend()plt.savefig('training_loss.png')plt.show()2.执行分类任务
import osimport shutilimport torchimport torchvision.transforms as transformsfrom PIL import Imagefrom torchvision.models import resnet18
# 定义类别标签classes = ['a.美少女', 'b.截图与杂图', 'c.动物', 'd.漫画'] # 根据你的实际类别名称修改
# 创建对应的类别文件夹output_folder = '分类结果' # 保存分类结果的主文件夹os.makedirs(output_folder, exist_ok=True)for class_name in classes: os.makedirs(os.path.join(output_folder, class_name), exist_ok=True)
# 加载模型model = resnet18()num_ftrs = model.fc.in_featuresmodel.fc = torch.nn.Linear(num_ftrs, len(classes))model.load_state_dict(torch.load('model.pth'))model.eval()
# 图像预处理transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])
# 批量分类并保存到对应文件夹函数def classify_and_save_images(folder_path, model, transform, classes, output_folder): for filename in os.listdir(folder_path): if filename.endswith(('.jpg', '.jpeg', '.png')): # 支持的图像格式 image_path = os.path.join(folder_path, filename) image = Image.open(image_path).convert('RGB') image = transform(image) image = image.unsqueeze(0) # 添加批次维度
# 进行预测 with torch.no_grad(): outputs = model(image) _, predicted = torch.max(outputs, 1)
# 获取预测类别 predicted_class = classes[predicted.item()]
# 保存图片到对应类别文件夹 destination_folder = os.path.join(output_folder, predicted_class) shutil.copy(image_path, destination_folder) print(f'Image: {filename}, Predicted: {predicted_class}, Saved to: {destination_folder}')
# 设置文件夹路径test_folder = 'xxx/需要分类的图片' # 替换为你的“测试”文件夹路径
# 调用分类并保存函数classify_and_save_images(test_folder, model, transform, classes, output_folder)
print('Classification and saving complete.')三、代码解析
1.训练模型代码解析
我使用的是PyTorch框架,结合torchvision库中的功能,来训练一个基于ResNet18的图片分类模型。
(1)导入必要的库
import torchimport torchvisionimport torchvision.transforms as transformsfrom torch.utils.data import DataLoader, Datasetfrom torchvision.datasets import ImageFolderfrom torchvision.models import resnet18from PIL import Imagefrom tqdm import tqdmimport matplotlib.pyplot as plttorch和torchvision:用于深度学习模型的构建和训练。transforms:用于数据预处理。DataLoader,Dataset:用于数据加载和管理。ImageFolder:一种常用的数据集加载方式,可以从文件夹结构读取分类图像数据。PIL.Image:用于图像处理。tqdm:进度条显示。matplotlib.pyplot:用于绘制图表。
(2)数据预处理
# 数据预处理transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])- 将所有图像调整为224x224像素。
- 转换为张量。
- 标准化图像数据。
(3)加载数据集
# 加载数据集dataset = ImageFolder(root='xxx/dataset', transform=transform)dataloader = DataLoader(dataset, batch_size=32, shuffle=True)- 使用
ImageFolder从指定目录加载数据,该目录下应按照类别分文件夹存放图像。 - 数据集被封装为
DataLoader,便于批量训练。
(4)加载预训练的ResNet18模型
# 使用本地的预训练ResNet模型model = resnet18()state_dict = torch.load('models/resnet18-f37072fd.pth')model.load_state_dict(state_dict)- 加载模型架构。
- 加载预训练权重。
(5)修改模型以适应新的分类任务
# 获取类别数量num_classes = len(dataset.classes)
# 修改最后一层以适应新的分类任务num_ftrs = model.fc.in_featuresmodel.fc = torch.nn.Linear(num_ftrs, num_classes)- 确定输出类别数。
- 替换模型的最后一层,以匹配新任务的输出需求。
(6)定义训练过程:
# 训练模型criterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
num_epochs = 10 # 根据需要调整
# 记录每个epoch的loss值loss_values = []
for epoch in range(num_epochs): epoch_loss = 0.0 with tqdm(total=len(dataloader), desc=f'Epoch {epoch+1}/{num_epochs}') as pbar: for inputs, labels in dataloader: optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() epoch_loss += loss.item() pbar.set_postfix({'loss': epoch_loss / (pbar.n + 1)}) pbar.update(1)
avg_loss = epoch_loss / len(dataloader) loss_values.append(avg_loss) print(f'Epoch {epoch+1}/{num_epochs}, Loss: {avg_loss}')- 选择损失函数:交叉熵损失。
- 选择优化器:随机梯度下降(SGD),设置学习率为0.001,动量为0.9。
- 设置迭代轮数。
- 进行模型训练,记录每个epoch的平均损失。
(7)保存模型
# 保存模型torch.save(model.state_dict(), 'model.pth')- 保存训练后的模型权重至本地。
(8)绘制训练损失变化图
# 绘制并保存loss值图表plt.figure()plt.plot(range(1, num_epochs + 1), loss_values, label='Training Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.title('Training Loss over Epochs')plt.legend()plt.savefig('training_loss.png')plt.show()- 使用
matplotlib绘制训练过程中每个epoch的损失变化曲线。 - 保存和显示图表。
2.执行分类任务代码解析
(1)定义类别标签和创建分类结果的文件夹
# 定义类别标签classes = ['a.美少女', 'b.截图与杂图', 'c.动物', 'd.漫画'] # 根据你的实际类别名称修改
# 创建对应的类别文件夹output_folder = '分类结果' # 保存分类结果的主文件夹os.makedirs(output_folder, exist_ok=True)for class_name in classes: os.makedirs(os.path.join(output_folder, class_name), exist_ok=True)classes列表包含了所有可能的类别名称。这些名称需要与你的数据集类别相对应。- 在指定的
output_folder目录下创建与classes列表中相同名称的子文件夹,用于保存分类后的图片。
(2)加载模型
# 加载模型model = resnet18()num_ftrs = model.fc.in_featuresmodel.fc = torch.nn.Linear(num_ftrs, len(classes))model.load_state_dict(torch.load('model.pth'))model.eval()- 加载ResNet18模型架构。
- 修改模型的最后一层全连接层,使其输出节点数等于类别数。
- 从之前训练好的
model.pth文件加载模型权重。 - 设置模型为评估模式(
model.eval()),这是在进行预测时必要的步骤。
(3)定义图像预处理:
# 图像预处理transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])- 使用
torchvision.transforms定义了一系列的图像预处理操作,包括缩放、转换为张量以及标准化。
(4)批量分类并保存图片到对应文件夹的函数:
# 批量分类并保存到对应文件夹函数def classify_and_save_images(folder_path, model, transform, classes, output_folder): for filename in os.listdir(folder_path): if filename.endswith(('.jpg', '.jpeg', '.png')): # 支持的图像格式 image_path = os.path.join(folder_path, filename) image = Image.open(image_path).convert('RGB') image = transform(image) image = image.unsqueeze(0) # 添加批次维度
# 进行预测 with torch.no_grad(): outputs = model(image) _, predicted = torch.max(outputs, 1)
# 获取预测类别 predicted_class = classes[predicted.item()]
# 保存图片到对应类别文件夹 destination_folder = os.path.join(output_folder, predicted_class) shutil.copy(image_path, destination_folder) print(f'Image: {filename}, Predicted: {predicted_class}, Saved to: {destination_folder}')- 函数
classify_and_save_images接收文件夹路径、模型、预处理方法、类别列表和输出文件夹路径作为参数。 - 遍历指定文件夹下的所有图片文件,只处理常见的图像格式(如.jpg、.jpeg、.png)。
- 对每张图片进行预处理,并添加批次维度,准备送入模型。
- 使用模型进行预测,获取预测的类别。
- 将图片复制到对应的类别文件夹中,并打印出分类结果和保存位置。
(5 )执行分类与保存操作:
# 设置文件夹路径test_folder = 'xxx/需要分类的图片' # 替换为你的“测试”文件夹路径
# 调用分类并保存函数classify_and_save_images(test_folder, model, transform, classes, output_folder)
print('Classification and saving complete.')- 指定需要分类的图片所在的文件夹路径。
- 调用
classify_and_save_images函数,开始分类并保存图片。
四、总结
- 在大模型时代,传统的机器学习当然还有其重要的使用价值,毕竟不可能所有的任务都要上昂贵的大模型,很多简单、廉价的任务传统的机器学习模型完全可以胜任
- 我希望着手开始构建一个蔚蓝档案角色的数据集,训练出一个专门用于ba角色分类的ResNet模型。
- 能否实现抓取、分类、筛选、放大全自动化流程,实现美图自由?不知道模型是否有“审美”的概念,可以自动剔除掉低质量(指绘画质量)的插画。理论上讲我觉得是没问题的,等未来视觉大模型进一步降价还可以考虑使用视觉大模型来筛选。